
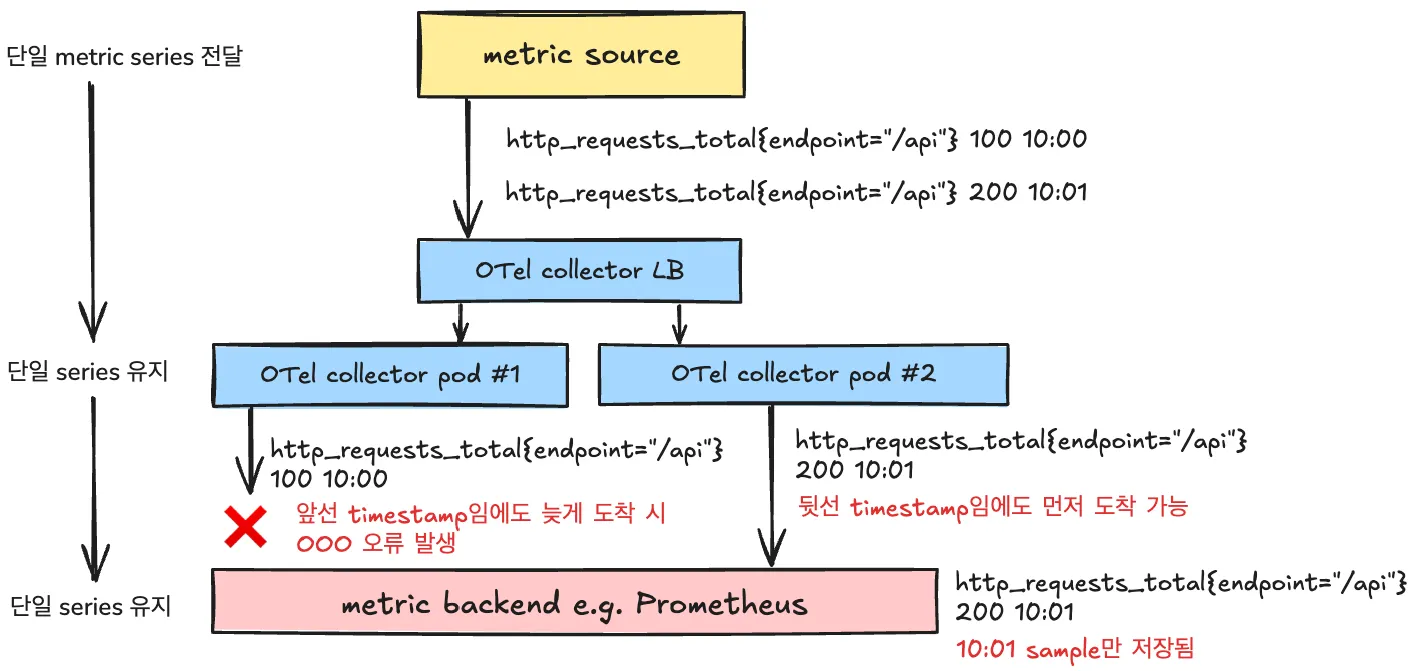
다수의 OTel collector instance 운용 시 OOO 오류가 발생한 경우의 예시
Introduction
Opentelemetry Collector의 metric backend로 AMP(Amazon Managed Prometheus)로 사용할 경우 발생 가능한 out of order sample 오류의 처리에 대한 논의이다. 본 오류 해결에 꽤나 오래 고생했는데, OTel slack 채널을 포함하여 본 오류에 대한 언급은 많을 뿐 해결안까지 정리된 문서는 당쵀 보이질 않았기 때문이다.
Summary
•
Prometheus는 out_of_order_time_window 옵션을 켜지 않으면 동일 metric series에서 순서가 역전된 sample 유입을 거부함과 동시에 out of order sample 오류를 뱉는다.
•
OpenTelemetry Collector는 HA 및 scaling을 위해 다수의 instance 구성을 지원하며(gateway 모드), 이 구성은 필연적으로 metric sample의 순서 역전을 유발한다.
•
AMP는 out_of_order_time_window 옵션을 지원하는 Cortex 제품 계열임에도, 이를 지원하지 않는다. 이에 따른 대안은 OTel collector instance의 식별자를 metric에 붙임으로 metric series를 OTel collector instance 별로 분리하는 것이다.
•
다중 pod 운용이 고려되지 않은 appolication metric 등 유사 상황이나 사용성을 위해 k8sattributes processor를 운용한다. 이는 OOO 오류를 줄이는 역할도 함께 한다.
오류 증상
(그리 크지 않은) metric traffic이 발생할 경우, AMP(Amazon Managed Prometheus)는 다수의 out of order sample (OOO) 오류를 Opentelemetry Collector의 prometheusremotewrite exporter로 응답한다. 이는 데이터 유실로 이어지는 무시하기 어려운 문제인데, 전체 sample 중 작게는 0.5%에서 많게는 50% 이상까지 발생이 목격되었다. 이는 OpenTelemetry native 메트릭 및 Prometheus 메트릭 모두에서 발생했다.
본 오류는 OpenTelemetry exporter가 생성하는 otelcol_exporter_send_failed_requests 메트릭 및 OpenTelemetry exporter 로그를 통해 확인 가능하며 아래는 각각의 예이다.
•
otelcol_exporter_send_failed_requests 메트릭 예(붉은 색. 약 3%의 오류를 보여주고 있음)
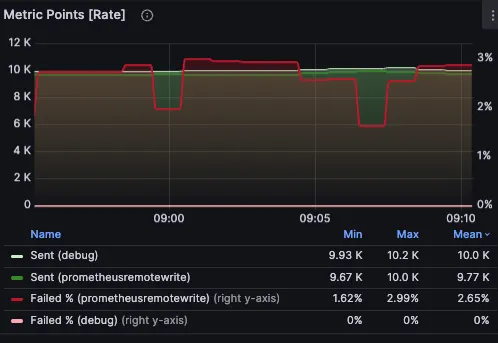
•
오류 로그 예. 상기 메트릭에서 드러난 전송 오류의 원인이 out of order sample 에 있음을 확인 가능하다.
2024-11-14T21:59:18.665Z error internal/queue_sender.go:100 Exporting failed. Dropping data. {"kind": "exporter", "data_type": "metrics", "name": "prometheusremotewrite", "error": "Permanent error: Permanent error: Permanent error: remote write returned HTTP status 400 Bad Request; err = %!w(<nil>): maxFailure (quorum) on a given error family, addr=x.x.x.x:9095 state=ACTIVE, rpc error: code = Code(400) ... err: out of order sample. timestamp=2024-11-14T21:59:15.639"}], "dropped_items": 2893}
go.opentelemetry.io/collector/exporter/exporterhelper/internal.NewQueueSender.func1
go.opentelemetry.io/collector/exporter@v0.110.0/exporterhelper/internal/queue_sender.go:100
go.opentelemetry.io/collector/exporter/internal/queue.(*boundedMemoryQueue[...]).Consume
go.opentelemetry.io/collector/exporter@v0.110.0/internal/queue/bounded_memory_queue.go:52
go.opentelemetry.io/collector/exporter/internal/queue.(*Consumers[...]).Start.func1
go.opentelemetry.io/collector/exporter@v0.110.0/internal/queue/consumers.go:43
Prolog
복사
오류 발생 원인
기본적으로 Prometheus는 동일 metric series에 대해 sample의 append만 가능하여, 마지막으로 append된 sample의 timestamp보다 같거나 이전 sample의 삽입을 거부하며, OOO 오류는 본 거부의 직접적 결과이다.
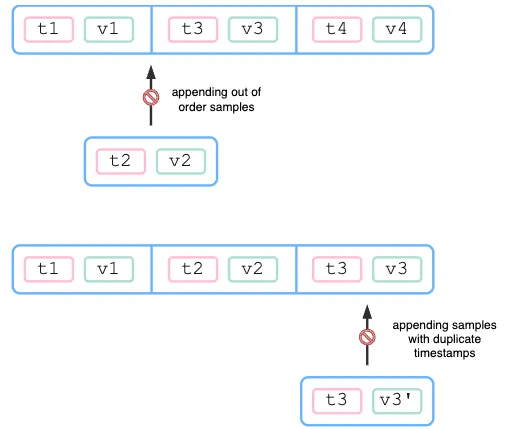
중도 삽입 또는 동일 timestamp 삽입 거부를 나타내는 그림. 출처: https://promlabs.com/blog/2022/12/15/understanding-duplicate-samples-and-out-of-order-timestamp-errors-in-prometheus/
위의 거부 상황은 아래 OpenTelemetry collector 환경, 특히 gateway 모드에서 별다른 설정을 하지 않는 이상 ‘아주 쉽게’ 만들어진다.
맨 앞의 그림은 다수의 OTel collector 운용 시 OOO 오류가 발생한 경우의 예시로, OTel Collector가 없을 경우 timestamp 순서대로 metric backend로 도착하여 이슈가 없을 metric이 다수의 instance를 운용하는 OTel Collector로 인해 순서 역전이 발생할 수 있음을 보여준다(OpenTelemetry Collector는 scaling 및 HA를 위해 다수의 instance로 운용되기 마련이다).
순서 역전은 지연에 의한 것으로, network의 본래적 속성에 의할 뿐 아니라(LB와 pod 사이의 지연), collector 내부의 batch processor 및 exporter 내부의 sending queue에서도 발생 가능하다.
참고로 Otel은 Single Writer 원칙을 표방한다(Prometheus도 동일). Single writer 원칙의 원 문장은 ‘All metric data streams within OTLP MUST have one logical writer’으로, 각각의 모든 metric data stream의 writer는 단일해야함을 의미한다. 하지만 writer 개념이 metric 생성 주체 뿐 아니라 collector instance도 포함될 경우, otel collector는 다수의 instance, 즉 다수의 writer를 지원하는 구조이기에 본 원칙을 쉽게 위배 가능하다.

해결안
out_of_order_time_window 란 Prometheus configuration 값을 적절히 설정함으로(default: 0s) 해결 가능하다. out_of_order_time_window 는 일정 윈도우에 대해서는 순서가 맞지 않는 metric가 설정된 window 이내의 timestamp일 경우 이를 수용함으로 OOO를 발생시키지 않는다. 무엇보다, OpenTelemetry 환경 시 이를 설정하기를 권장하는데, 그 이유 위의 OOO 발생 원인을 아래와 같이 언급한다.
the OpenTelemetry collector encourages batching and you could have multiple replicas of the collector sending data to Prometheus. Because there is no mechanism ordering those samples they could get out-of-order.


Prometheus 뿐 아니라 Cortex를 포함한 대부분의 타 Prometheus 호환 제품은 본 옵션 및 유사 옵션을 지원하는데, 내부적으로 Cortex를 사용한다고 알려진 AMP(Amazon Managed Prometheus)는 그렇지 않다.
AMP가 이를 지원하지 않는 정확한 원인은 밝혀져있지 않으나, out_of_order_time_window 상태가 experimental 임과 동시에 github에 close 되지 않은 이슈가 있기는 하다. 공식 문서는 OOO의 원인을 잘못된 클라이언트 구성(incorrect setup of the client)으로 돌리고 있는데, 이는 잘못된 설명으로 보인다. 예컨데 분산 환경에서 network 지연에 의한 순서 역전은 클라이언트 구성과는 관계가 없기 때문이다.


AMP 이외의 Prometheus 호환 제품 별 out_of_order_time_window 및 유사 옵션 지원 현황
•
Thanos: 확인되지 않음. 지원을 하는 듯한 몇몇 문서가 보이나 이를 명시한 문서는 발견 못함.•
Cortex: AMP가 내부적으로 사용한다고 알려진 Cortex 역시 out_of_order_time_window와 동일한 명칭으로 지원한다. 참조:  CortexConfiguration file
CortexConfiguration file•
Grafana Mimir: out_of_order_time_window와 동일한 명칭으로 지원하는데, 내부적으로 Cortex를 사용한다고 알려져 있기에 이는 당연한 듯 하다. 참조:  Grafana LabsConfigure out-of-order samples ingestion | Grafana Mimir documentation
Grafana LabsConfigure out-of-order samples ingestion | Grafana Mimir documentation•
VictoriaMetrics: out_of_order_time_window와 동일한 명칭의 옵션은 확인되지 않았으나 아래 논의에서 지원함을 확인. 참조: AMP에서의 해결안
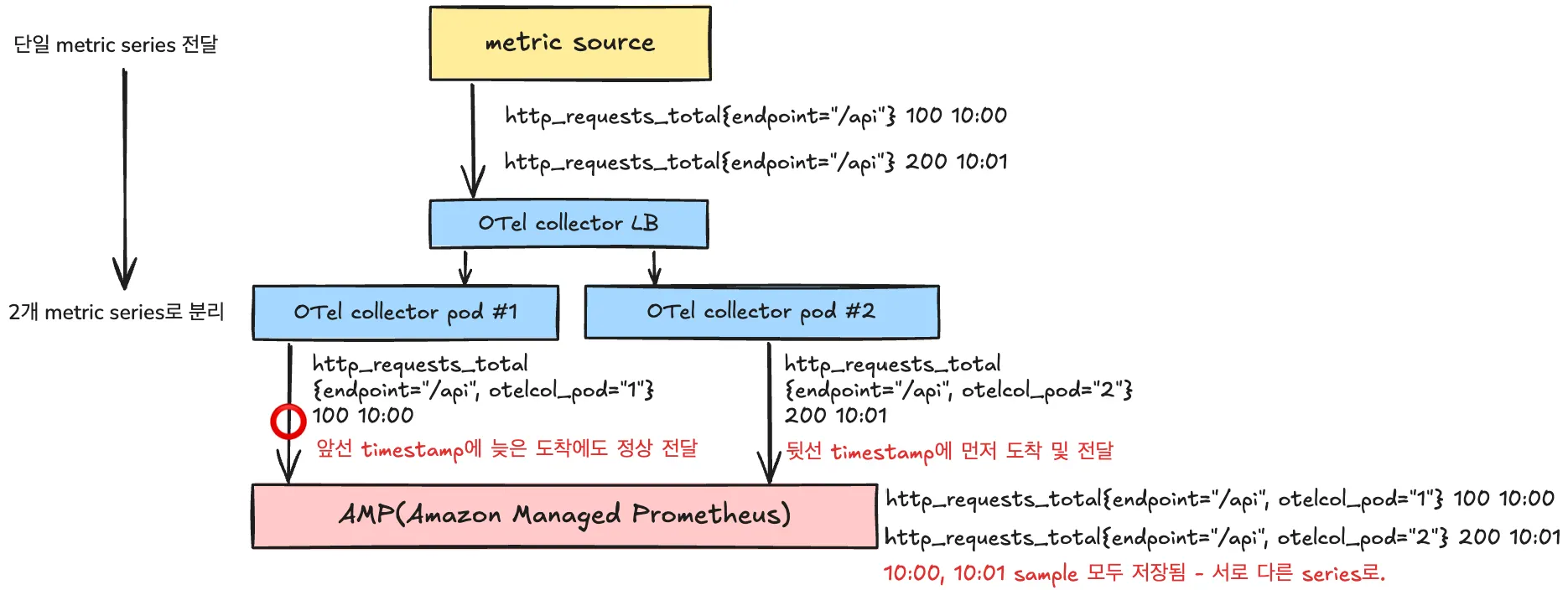
각 metric sample에 otelcol_pod란 label로 해당 collector pod의 식별자를 추가함으로, OOO 오류를 피한다.
out_of_order_time_windw 옵션을 지원하지 않는 AMP에서는 OTel collector에서 각 metric에 collector 자신의 식별자를 붙이는 방법으로 해결 가능하다. 이는 OOO 오류의 발생 조건인 ‘동일 metric series’을 피하는 전략으로, 이 식별자를 붙임으로 각 metric series는 식별자 갯수 만큼 series로 나뉘게 됨으로 자연스럽게 OOO 오류를 피하게 된다(동일 collector pod를 거치는 모든 metric은 처리된 sample간 순서가 보장됨을 전제로 한다).
exporters:
prometheusremotewrite:
...
external_labels:
otelcol_pod: "${env:POD_NAME}"
...
YAML
복사
otelcol_pod 식별자를 각 metric sample에 label로 붙이는 방법은 tramsform processor 사용 등 여러가지가 있으나, prometheusremotewrite exporter의 external_labels field에서 처리하는 방법이 가장 자연스럽다.
위 방법은 Prometheus 계열 제품에서 일반적으로 사용되는 듯 하다. 예컨데 Thanos에서는 replica 란 이름으로, Prometheus는 prometheus_replica 란 명칭을 해당 식별자(위 예에서는 otelcol_pod)를 위한 label 이름으로 사용되는 듯 보인다.
otelcol_pod 란 이름은 임의로 붙인 것이기에 달리 가도 무방하나, 적어도 AMP에서는 __replica__ 란 명칭은 피해야 한다. AMP를 포함한 Cortex 계열 제품은 __replica__ 명칭에 대해 달리 동작하는데, 이로 인해 ‘잘못된’ metric sample 삭제로 이어질 수 있기 때문이다(실제 이로 인해 꽤나 고생했다). 이에 대해서는 Appendix: Cortex 계열 제품에서의 __replica__ pod 식별자에 관하여 에서 다룬다.
AMP 공식 문서의 잘못된 가이드
AMP는 OTel Collector 사용 시, __replica__ 이름으로 위와 동일한 방법으로 추가하라는 가이드를 하는데(OTel Amazon 배포판 기준을 논하지만 마찬가지이다), 이는 사실 상 잘못된 설명이다. 이에 대한 자세한 내용은 Appendix: Cortex 계열 제품에서의 __replica__ pod 식별자에 관하여를 참고한다.
본 오류 관련 기타 (불완전) 해결안
아래는 시도해보았던 기타 해결안으로 OOO 오류가 완화되긴 했지만 완전 제거에는 실패한 안이다. 다만 아래 중 k8sattributes processor 사용은 OOO 오류 건 이외에 사용성에도 의미가 있으므로, 앞선 해결안 적용과 함께 사용하는 것이 좋아 보인다.
target_info metric 제거 및 k8sattributes processor 추가
target_info metric에서 다수 발생함을 발견. 해당 metric을 제거한 후 상당부분 완화 또는 제거. 하지만 여전히 일부 시스템에서 OOO 오류가 약 2~5% 내외로 지속 발생하였다. 참고로 target_info 메트릭은 Prometheus remotewrite receiver에서 (별도 설정하지 않는 이상) 전송하는 메트릭으로, OOO 이슈가 아니더라도 제거하는 것이 좋은데, 해당 메트릭 목적이 수집 대상(target)의 resource 정보를 얻기 위한 것으로, resource 정보는 OTel에서 k8sattributes processor를 통해 아래와 같이 얻어 label에 추가 가능하기 때문이다.
processor:
k8sattributes:
auth_type: "serviceAccount"
pod_association:
- sources:
- from: connection
extract:
metadata:
- k8s.namespace.name
- k8s.container.name
- k8s.pod.name
...
YAML
복사
나아가 k8sattributes processor는 OOO 이슈가 아니더라도 상시 넣는 것이 좋아 보이는데, 여러 pod에서 운용되는 것이 고려되지 않은 app metric이 다수의 pod에서 운용될 때의 metric 중복 이슈 제거 및 promQL 운용 시 표준적으로 grouping(e.g. namespace 별 grouping)에도 용이하기 때문이다.
추가로, Istio 환경에서는 k8sattributes processor를 정상 운용하기 위해, OpenTelemetry Collector의 annotation에 sidecar.istio.io/interceptionMode: TPROXY 를 설정해야 한다. 안하면 target IP가 Istio 내부에서만 사용되는 127.0.0.6로만 수집되어, k8sattributes processor가 정상적으로 k8s apiserver로부터 target resource 정보를 얻지 못한다.


참고: target_info란


Prometheus가 생성하는 수집 대상(target)에 대한 정보이다. job, instance (target 정보), version 등을 생성하여 관련 metric 생성 주체, 즉 target에 대한 정보를 보내어 해당 metric의 query에서 아래와 같이 사용 가능하도록 한다. query 대상 metric과는 별개의 metric에 있기에 query가 OTel의 그것에 비해 지저분하다.
# job, instance, k8s_cluster_name은 target_info metric의 label.
rate(http_server_request_duration_seconds_count[2m])
* on (job, instance) group_left (k8s_cluster_name)
target_info
Prolog
복사
Metric 별로 처리 collector instance 지정
동일 metric에 대해서는 동일 collector instance가 처리하도록 강제화하여 OOO 발생 조건을 제거하는 방법이다. 구체적으로 두 가지 방법이 있는데, 하나는 Kubernetes Service의 sessionAffinity 기능을 사용하는 것과 다른 하나는 OTel의 loadbalancing exporter를 사용하는 OTel Collector를 기존 OTel Collector 앞단에 추가하는 것이다. 테스트 결과 두 가지 모두 완화만 이루었을 뿐 완전한 제거에는 실패했다. 구체적인 이유는 밝혀지지 않았다.
참고로, loadbalancing exporter은 sessionAffinity 처럼 consistent hashing을 위한 것인데, routing key로 service name, metric 등을 사용 가능하여 sessionAffinity 의 cluster IP보다 더 세밀하게 routing 가능하다. 문제는 span, log와는 달리 metric이 development stability란 점이었는데, 테스트 결과 어쨌건 동작은 했다. 여전히 OOO 오류 제거가 아닌 완화 수준이었다는 점이 문제였지만.


opentelemetry-collector-contrib/exporter/loadbalancingexporter at main · open-telemetry/opentelemetry-collector-contrib
Contrib repository for the OpenTelemetry Collector - open-telemetry/opentelemetry-collector-contrib

https://github.com/open-telemetry/opentelemetry-collector-contrib/tree/main/exporter/loadbalancingexporter
OpenTelemetry loadbalancing exporter
제대로 동작한다 하더라도, 이들 방법 적용 시 특정 metric의 편중된 부하로 인해 특정 collector pod로 부하가 몰릴 수 있다는 점을 추가 고려해야할 듯 하다.
Appendix: Cortex 계열 제품에서의 __replica__ pod 식별자에 관하여
Cortex는 __replica__ label을 metric scrapper instance 식별자로 특별히 취급하여, 동일 metric series에 대해 다수의 __replica__ 값이 있을 경우 하나의 instance만 리더로 선출하여 리더를 통해 들어온 metric만을 ACCEPT하고 나머지는 DROP한다. 이는 HA를 이유로 동일 metric에 대해 다수의 scrapper instance가 수집하는 경우 sample의 중복을 제거하기 위한 전략이다(물론, 특정 리더가 일정시간 응답이 없으면 다른 값의 instance가 리더로 변경된다).


위 동작은 scrapper로서 pull 방식의 Prometheus를 가정한 내용으로, OTel collector, 특히 OTLP를 사용하는 metric은 push 방식에서는 맞지가 않다. push 방식에서는 정상적인 상황이라면 단일 metric series에 대해 각 metric sample의 timestamp의 중복이 발생 불가능하기 때문이다. 이 말은 OTel collector 사용 시 DROP이 있어선 안된다는 뜻이며, Cortex의 __replica__ label 처리 방식을 적용해서는 안된다는 의미이다. 물론 OOO 이슈 처리를 위한 해결안도 되지 않는다.
이는 Cortex의 동작 방식이기에 Cortex 계열 제품인 Grafana Mimir와 AMP(Amazon Managed Prometheus) 역시 위 설명과 동일한 방법으로 __replica__ label을 처리한다. 한편 AMP는 OTel Collector에 대해서도 __replica__ 를 쓰라고 가이드하는데, 앞선 설명에서의 이유로 이는 사실 상 잘못된 설명으로 보인다. 굳이 OTel Collector에 대해서도 가이드하려면 Prometheus의 경우와 동일하게 OTel Collector를 구성했을 경우에만, 그것도 pull 방식의 Prometheus metric에 대해서만 유효함을 명시해야할 것이다.

OpenTelemetry Collector 운용에 관한 AMP 공식 문서의 설명. 별다른 제약 조건에 대한 명시 없이 Prometheus의 그것과 동일하게 가이드하고 있으며, 이 경우 데이터 누락이 발생한다.