

Introduction
OpenTelemetry Collector에서 사실 상 필수로 사용하길 권장되는 component인 memory limit, Batch processor에 대한 논의로, 사실 상 아래 공식 README에 대한 요약이다.


Memory Limit Processor
Memory Limit Processor는 Out Of Memory(OOM) 오류 방지를 위함으로, 발생 전에 OpenTelemetry Collector로의 telemetry 인입을 거부하거나, garbage collection을 발생시킴으로 OOM 발생을 미연에 방지한다. 대상 telemetry는 metric, log, trace 전체이다.
구조
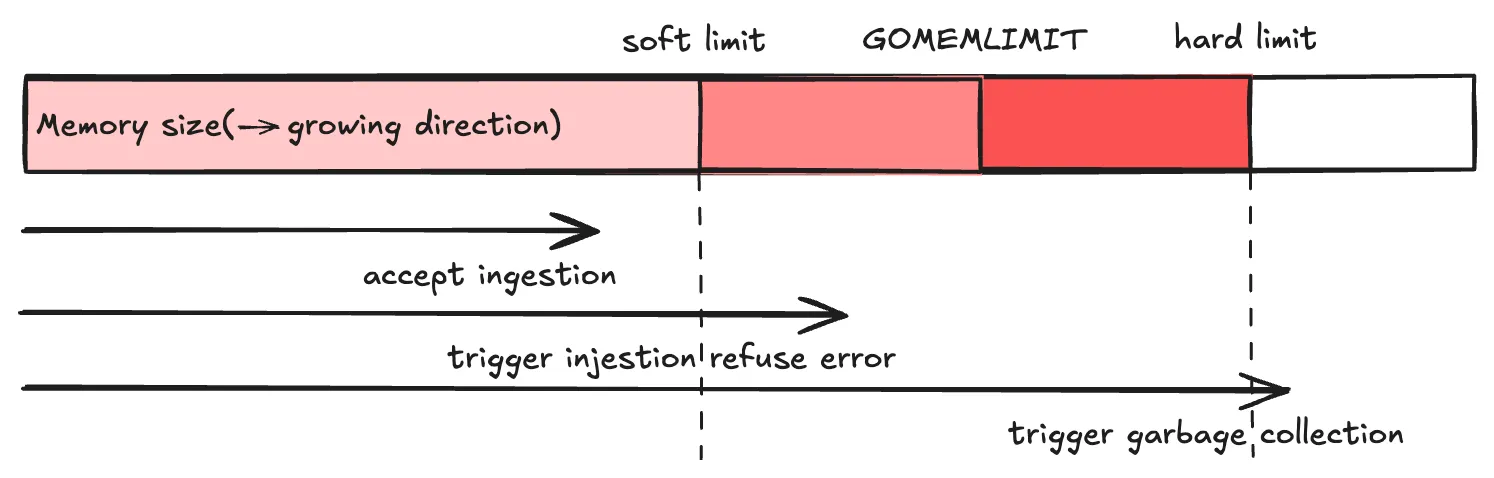
1.
hard limit: garbage collection 강제 발동 threshold. limit_mib 로 정의됨.
•
limit_mib(default: 0): process heap에 할당된 최대 메모리량. MiB 단위. process의 전체 메모리 사용량은 일반적으로 본 값보다 50MiB 더 사용함.
•
limit_percentage(default: 75): limit_mib에 대한 상대 값 버전. limit_mib와 동시 정의될 경우 우선순위가 낮음.
2.
soft limit: telemetry 인입 거부 threshold.limit_mib - spike_limit_mib 로 정의됨.
•
spike_limit_mib: 메모리 사용량 측정 간에 기대되는 최대 스파이크
•
spike_limit_percentage(default: 0): spike_limit_mib의 상대값 버전. hard limit이 아닌 전체 메모리량 기준 비유을 의미. limit_percentage 가 사용될 때만 유효
•
거부 시 본 processor에 앞선 component(e.g. receiver)에 오류를 전달. receiver는 본 오류 확인 시 데이터 전달을 재시도하는 것으로 기대됨.
◦
(Claude AI에 따르면) Prometheus receiver는 재시도하지 않고 해당 데이터를 drop. 비록 해당 주기의 데이터는 사라지더라도 다음 주기에 데이터를 가져올 것으로 기대. 반면 OTLP receiver는 OTLP client가 재시도를 하도록 429 또는 503 응답을 주거나, gRPC 상에서 flow control 신호를 client에 보냄으로 client로 하여금 전송 속도를 조절하도록 함.
(Claude AI 답변) backpressure에 대한 Prometheus, OTLP receiver 동작 방식
Best Practices
1.
collector의 적절한 resource 조절에 대한 대안이 아님: soft limit은 결국 데이터 유실로 이어질 수 있음(재시도 로직이 있다 하더라도 무한정 재시도는 할 수 없기 때문에). 따라서 soft limit, hard limit 값 등을 메모리 사용량을 확인함으로 적절히 조절해야(#4의 본 processor가 생성하는 metric을 상시 참고. 특히 refuse 건에 대해).
2.
Processor pipeline에 모든 타 processor 보다 앞에 놓아야: 이렇게 함으로 receiver로 memory 부하가 발생했을 때 receiver로 하여금 적게 데이터를 보내게 함으로 데이터 drop을 줄일 수 있음
3.
GOMEMLIMIT를 hard limit의 80% 설정 강력히 권장
4.
Memory Limit Processor가 생성하는 metric은 다음 참고
Batch Processor
Batch Processor는 전송 대상 데이터를 압축하고, outgoing connection 갯수를 줄이는 목적으로 사용한다. 대상 telemetry는 metric, log, trace 전체이다.
구조
기본적으로 batch의 크기 및 누적 시간을 기준으로 각 batch가 생성된다. 그리고 최대 크기를 넘길 경우 batch를 분리한다.
flowchart TB
subgraph "Batch Buffer"
B[데이터 누적]
C1[size 검사]
C2[timeout 검사]
C3[max size 검사]
end
subgraph "Batch Creation"
P1[batch 생성]
P2[batch 분할]
end
I[Injested metric, log, trace] --> B
B --> C1
C1 --> |"buffer size < send_batch_size"| C2
C2 --> |"time elapsed < timeout"| B
C1 --> |"buffer size >= send_batch_size"| C3
C2 --> |"time elapsed >= timeout"| C3
C3 --> |"buffer size <= send_batch_max_size"| P1
C3 --> |"bufer size > send_batch_max_size"| P2
P2 --> P1
P1 --> O[다음 프로세서]
classDef input fill:#f9f,stroke:#333,stroke-width:2px
classDef buffer fill:#bbf,stroke:#333,stroke-width:2px
classDef process fill:#bfb,stroke:#333,stroke-width:2px
classDef output fill:#fbb,stroke:#333,stroke-width:2px
class I input
class B,C1,C2,C3 buffer
class P1,P2 process
class O outputMermaid
복사
•
send_batch_size: 전송 trigger를 일으키는 telemetry의 갯수로서 단일 batch의 기준 크기. default는 8192.
•
timeout: 전송 trigger를 일으키는 batch 간 시간 간격으로 default는 200ms. 0일 경우 send_batch_size 보다 telemetry 갯수가 적더라도 즉시 전송이 시작됨.
•
send_batch_max_size : 단일 batch의 최대 크기(telemetry 갯수). 본 값을 넘어서면 batch는 분할된다. default는 0으로, 이 경우 단일 batch 크기 제한이 없음을 의미.
•
참고: send_batch_size 가 있음에도 send_batch_max_size 가 있는 이유는 buffer에 send_batch_max_size 를 넘어서는 telemetry 갯수가 위치할 수 있기 떄문.
Pipeline 상 Processor 순서에 관하여
하기 Processor 공식 문서에 따르면 processor 간의 순서는 매우 중요하며, pipeline 구조인 것을 감안하면 그게 당연하다. memory_limit 은 모든 processor 중 가장 앞에 위치하는 것을, 그리고 batch 는 sampling, filtering 및 metric에 변경을 가하는 processor 뒤에 위치하는 것을 논한다. Example 에 pipeline 상 processor 순서를 나타내고 있다.
Example
env:
- name: GOMEMLIMIT
value: 640MiB # 1Gi * 0.85(limit_percentage) * 0.8 80% of hard memory limit is highly recommended by Official README.
config:
processors:
memory_limiter:
check_interval: 1s # recommended by official README
limit_percentage: 85
spike_limit_percentage: 17 # default is 20% of hard limit. 17 = 0.85 * 0.2
batch: # https://github.com/open-telemetry/opentelemetry-collector/blob/main/processor/batchprocessor/README.md
send_batch_size: 8192 # default 8192
send_batch_max_size: 0 # default 0, which means no limit on size.
timeout: 200ms # default 200ms
service:
pipelines:
metrics:
processors:
- memory_limiter # recommended to be the first in processors pipeline
- "Any sampling or initial filtering processors"
- "Any processor relying on sending source from Context (e.g. k8sattributes)"
- batch # place before any attribute, transform, sampling, filter processors as well as memory limit processor
- "Any other processors"
YAML
복사