
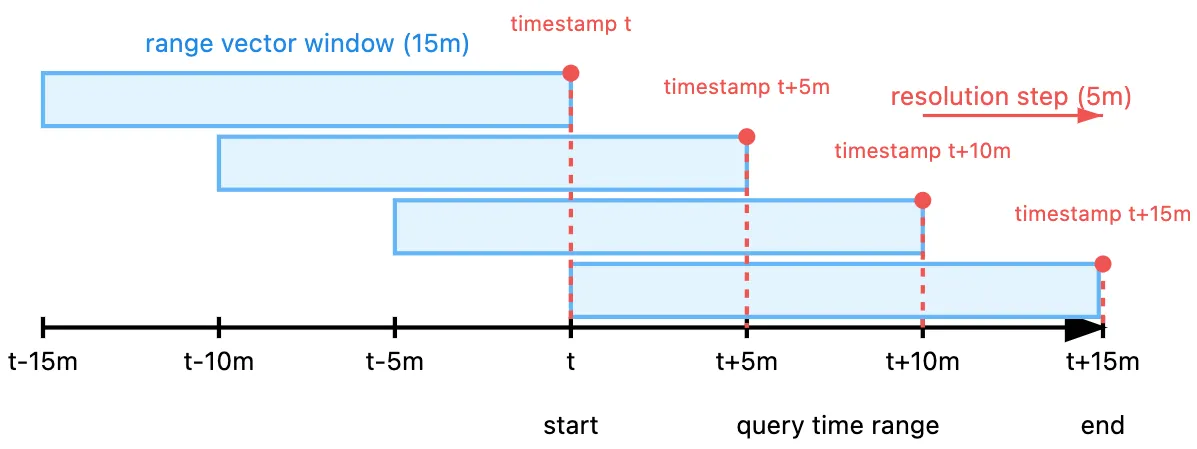
query time range, resolution step, range vector selector와의 관계
Introduction
Prometheus의 range query 사용 시 필히 마주하게 되는 세가지 시간 개념 - range vector selector, resolution step, query time range 간의 관계에 대해 논한다. 이외에 추가로 rate() 와 irate() 도 간단히 비교한다.
이들 개념은 공통적으로 유사한 시간 간격 개념을 갖고 있어 해깔리기 딱 좋다. 게다가 Grafana 사용 시 resolution step은 자동 설정으로 두기 때문에, query를 직접 만들지 않고 visualization만 다룰 경우 존재 자체를 인지하기 어렵기도 하다. 내가 그랬다.
참고로, range query는 time series 그래프 등을 위한 시간 범위 데이터를 산출하는 반면 이에 대비되는 instant query는 (주로) 특정 시점 데이터를 산출하여 gauge chart 등에 사용한다.
전반의 용어와 개념은 아래 Prometheus 공식 문서와 Prometheus 주 개발자의 블로그를 참고하였다. 이외에 모든 그림과 code는 Claude (AI)로 생성하였다.



예제: 20분간의 RPS(초당 요청수)에 대한 time series 구하기
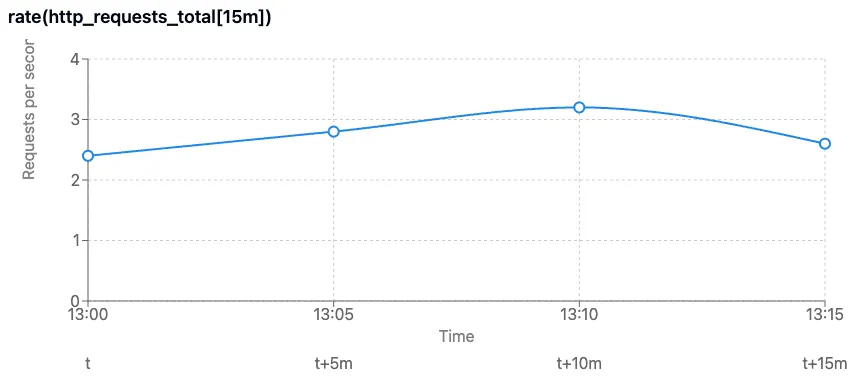
예를 들어 설명한다. 위 그래프는 20분간(13:00 ~ 13:15)의 RPS에 대한 time series를 나타내어, 값 간의 간격은 5분이다. 이 그래프를 그리기 위한 Prometheus로의 질의 방법은?
아래는 이 질문에 대한 직접적인 답으로, Prometheus의 query_range HTTP API에 대한 request 및 response이다. response의 values 필드에 있는 값을 보면 위 그래프의 각 포인트를 나타냄을 알 수 있다.


GET /api/v1/query_range
?query=rate(http_requests_total[15m]) # range vector selector가 지정됨
&start=2024-12-08T13:00:00Z # query time range의 start가 지정됨
&end=2024-12-08T13:15:00Z # query time range의 end가 지정됨
&step=5m # resolution step이 지정됨
Python
복사
Prometheus HTTP request 예제
{
"status": "success",
"data": {
"resultType": "matrix",
"result": [
{
"metric": {
"job": "...",
"instance": "localhost:8080",
"handler": "/api/v1/query_range"
},
"values": [
[1702040400, "2.4"], // t (13:00:00)
[1702040700, "2.8"], // t+5m (13:05:00)
[1702041000, "3.2"], // t+10m (13:10:00)
[1702041300, "2.6"] // t+15m (13:15:00)
]
}
]
}
}
JSON
복사
Prometheus HTTP response 예제
문제는 위 결과가 어떻게 만들어지는지를 이해하는 것이다.
예제 분석
서두의 그림은 앞선 예제에 대한 개념 상의 Prometheus의 내부 계산 구조를 나타내는데, 세가지 시간 개념, 즉 range vector selector, resolution step, query time range 간의 관계를 함께 드러낸다. 참고로, t 는 앞선 예제의 13:00에 해당하고, range vector 4개 각각에 대한 query는 앞선 HTTP request의 query parameter 값에 해당한다.
계산은 일종의 sliding window 방식으로, resolution step에 따른 각 timestamp에 맞게 range vector의 위치가 정해져 각 window 별로 계산을 이룬다. 각 계산 결과의 타입은 각 timestamp 기준의 instant vector가 되고, 이들 instant vector를 모은 결과로 최종 output인 range vector가 만들어진다.
•
Query time range: 전체 쿼리에 대한 시간 범위. Grafana에서는 사용자가 time picker UI를 통해 직접 설정한다. query_range API에서는 start, end parameter로 지정하고 결과에 둘 모두 포함된다(inclusive).
•
Resolution step (또는 step): output sample 간의 시간 간격. Grafana는 보통 이를 화면 pixel 등을 고려하여 자동으로 설정한다. 앞선 query_range API에서는 step parameter로 지정한다.
•
Range vector selector: 상기 그림에서 range vector window의 크기(15m)를 의미한다. range vector 내 마지막 sample의 timestamp가 output instant vector의 timestamp이다.
참고로, 이 selector에는 [5m] 등의 고정값을 지정할 수도 있지만, Grafana는 resolution step, query time range와 화면 해상도가 고려된 값이 자동 지정될 수 있도록 $__interval, $__rate_interval, $__range 등의 template variable을 제공한다.

instant vector, range vector 란
•
instant vector: 각 time series 마다 동일한 timestamp의 단일 sample로 구성된 time series의 집합
•
range vector: 연속된 시간 범위의 instant vector의 집합으로, 각 time series 마다 일정 시간 범위의 다수 sample을 가진다.
이외에 query time range란 용어는 Prometheus 공식 문서가 아닌 Cortex 공식 문서에서 일반 명사로 사용된 것을 빌린 것이고, range vector window는 range vector에 window의 의미를 임의로 추가한 용어이다.
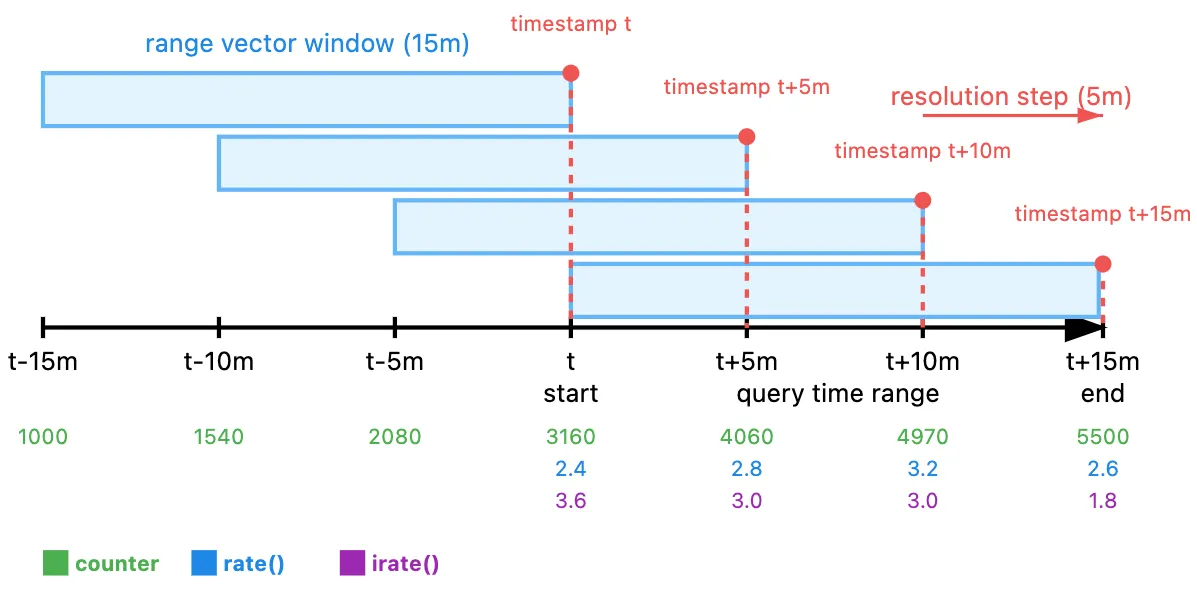
상기 예제의 각 range vector내 samples
아래는 위 예제의 각 range vector 내 sample이 구체적으로 어떤 모습을 띨 수 있는지를 보여준다. 이 뿐 아니라 상기 예제에서 사용된 rate() 와, 이 함수와 깊게 관련된 irate() 계산 방법과 결과도 추가했다. 참고로, 각 sample 간의 간격이 resolution step과 동일하게 5m 인데 이는 설명 편의상 맞춘 것에 불과하다. 이외에 코드를 까서 분석한 것이 아니라, 실제 계산 방법과는 차이가 있을 수 있다. 하지만 rate() 이 average를 나타낸다는 점에서 적어도 개념 상 틀리지는 않다.
GET /api/v1/query_range
?query=http_requests_total
&start=2024-12-08T12:45:00Z
&end=2024-12-08T13:15:00Z
&step=5m
Python
복사
위 예제의 각 range vector 내 sample을 구하기 위한 request 예
{
"status": "success",
"data": {
"resultType": "matrix",
"result": [
{
"metric": {
"job": "api-server",
"instance": "localhost:8080",
"handler": "/api/v1/query_range"
},
"values": [
// For t (13:00:00)
[1702039500, "1000"], // 12:45:00
[1702039800, "1540"], // 12:50:00
[1702040100, "2080"], // 12:55:00
[1702040400, "3160"], // 13:00:00
// rate = (3160-1000)/900 = 2.4
// irate = (3160-2080)/300 = 3.6
// For t+5m (13:05:00)
[1702039800, "1540"], // 12:50:00
[1702040100, "2080"], // 12:55:00
[1702040400, "3160"], // 13:00:00
[1702040700, "4060"], // 13:05:00
// rate = (4060-1540)/900 = 2.8
// irate = (4060-3160)/300 = 3.0
// For t+10m (13:10:00)
[1702040100, "2080"], // 12:55:00
[1702040400, "3160"], // 13:00:00
[1702040700, "4060"], // 13:05:00
[1702041000, "4970"], // 13:10:00
// rate = (4970-2080)/900 = 3.2
// irate = (4970-4060)/300 = 3.0
// For t+15m (13:15:00)
[1702040400, "3160"], // 13:00:00
[1702040700, "4060"], // 13:05:00
[1702041000, "4970"], // 13:10:00
[1702041300, "5500"], // 13:15:00
// rate = (5500-3160)/900 = 2.6
// irate = (5500-4970)/300 = 1.8
]
}
]
}
}
Python
복사
위 예제의 각 range vector 내 sample 목록. 각 window내 사용되는 sample을 표현하기 위해 sample을 중복해서 표시했다.
아래 그림은 앞선 그림에 위 response의 값(counter)과 rate() , irate() 를 적용한 결과를 나타낸다.
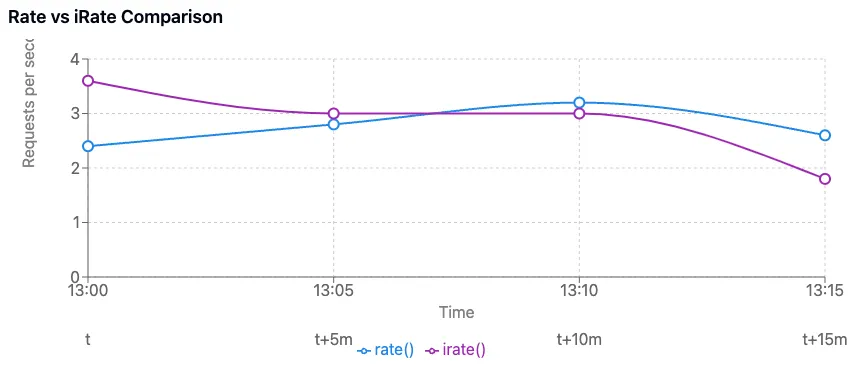
rate() vs irate()
본 글 주제에 약간 벋어나긴 한 내용인데, 예제에 사용한 rate() 에 깊게 관계된 내용이라 추가한다.
Prometheus에는 변화율을 나타내는 rate() 뿐 아니라 이와 매우 유사한 irate() 가 있는데, average가 아닌 window 내 마지막 2개 sample만 사용하여 계산한다. 이들 둘 간의 용도 차이를 Prometheus 공식 문서는 아래와 같이 설명한다(한글 자동 번역).
irate 는 변동성이 크고 빠르게 움직이는 카운터를 그래프로 그릴 때만 사용해야 합니다. rate알림과 느리게 움직이는 카운터에 사용해야 합니다. irate 는 비율의 짧은 변화로 인해 FOR절이 재설정될 수 있고 드문 스파이크로만 구성된 그래프는 읽기 어렵습니다.
이외에 아래와 같은 특징이 논의되곤 하는데, 추가로 irate() 가 전반으로 처리 속도가 경험적으로 더 빠른데 이에 대한 원인은 확인 못했다.
•
irate()는 rate() 대비 spike를 잘 잡지만 전반의 트랜드를 볼때는 rate() 를 쓴다.
•
rate() 는 긴 query time range에, irate() 는 짧은 경우에 쓴다.
spike를 잘 잡는 특성, 변동성이 크고 빠르게 움직이는 카운터이란 irate() 용도는 두 인접 sample 간 value 차이를 그대로 반영한다는 점, 즉 average의 평탄화 효과가 없다는 점에서 이해 가능하다. 또한, 두 sample 이외의 나머지 sample의 값 및 범위가 무시되는 irate() 동작 특성은 드문 스파이크로만 구성된 그래프를 읽기 어렵다는 점과 짧은 query time range에서 사용이 필요하다는 점의 원인으로 이해된다(query time range가 클 수록 무시되는 sample 수가 증가한다).
아래 그래프는 위 예제에 대한 rate() 과 irate() 적용 결과의 비교로서, irate() 가 변화 폭이 더 큰 특성을 보여주고 있다.
기타: lookback delta
위 예제는 query에 사용된 sample의 timestamp가 산출 결과의 timestamp가 딱 들어맞게 표현되었는데, 이는 설명의 용이성을 위해 조정한 것으로 real world에서는 그렇지 못하기 마련이다.
query 결과의 timestamp는 평가 시점을 의미하는 것이지 sample 자체의 실제 timestamp가 아니다. query 계산에 사용되는 sample은 평가의 특정 시점이 아닌, 평가 시점부터 이보다 이른 일정 시점까지의 범위 내에 위치하며, 해당 범위를 가리켜 lookback delta 라 한다. default 값은 5분. 자세한 내용은 아래 링크를 참고한다.


참고로, sample 자체의 실제 timestamp를 얻는 방법은 확인되지 않았다.