
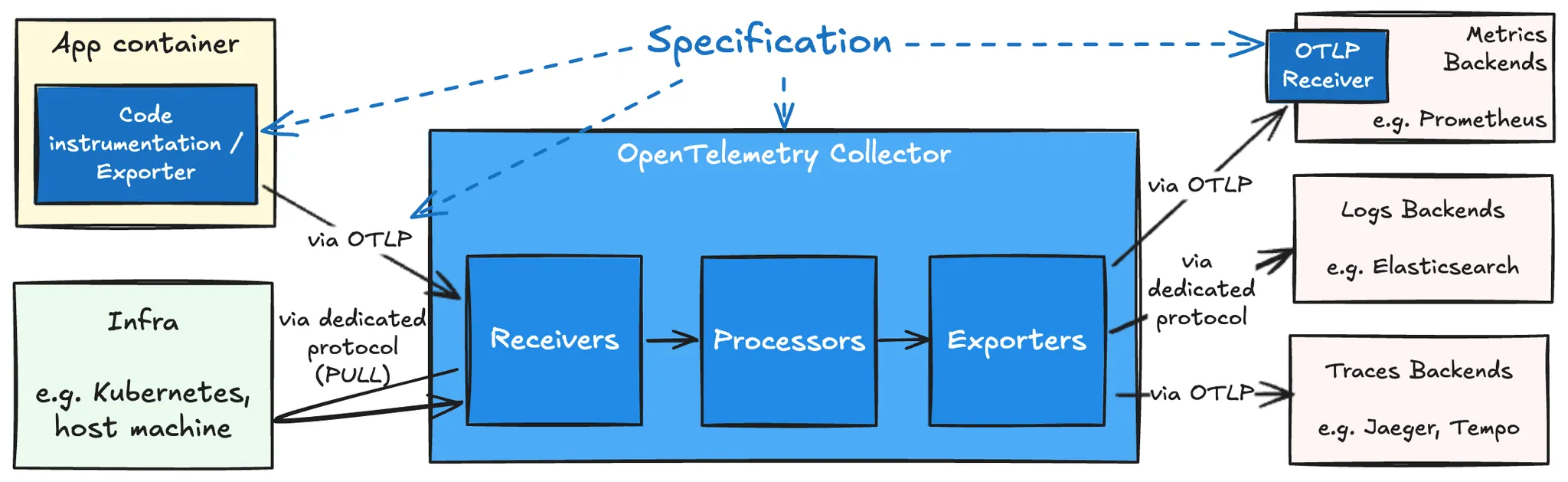
OpenTelemetry의 3가지 요소인 Specification, Instrumentation, Collector의 o11y eco-system 상 위치로서, 점선은 design time에 미치는 영향을, 실선은 데이터 전달 방향을 의미한다. Architecture 에서 상세히 설명한다.
Introduction
Kubernetes 환경에서의 Observability용 최적 component 조합 검토 중 OpenTelemetry가 수시로 언급됨을 발견. 뿐만 아니라 component 제품마다 이에 대한 지원을 항시 언급. 이즈음 되면 OpenTelemetry는 무시할 수 없는 무엇이 되어버렸다는 뜻.
이 글은 OpenTelemetry에 대한 사용자 관점의 overview이다. 이외에 추후 관련 구현 및 상세 검토를 위해 주요 내용에 대해서는 해당 참조 문서 링크를 달았다.
다음은 OpenTelemetry 공식 홈페이지이자 본문에서 주로 참조한 문서.

Why OpenTelemetry?
1.
MLT 통합 계측: Observability의 핵심인 signal, 즉 MLT(Metrics, Logs, Traces)를 통합 계측, 처리함으로 프로세스 및 아키텍처를 단순화할 뿐 아니라 이들 데이터간 correlation 기반 분석을 촉진한다.
2.
표준화 : MLT 데이터 수집에 대한 표준화된 방법 제공으로 다양한 관찰 도구 및 플랫폼과 더 쉽게 통합 가능하다. 이러한 표준화는 일관성과 호환성을 촉진한다.
3.
최상위권 CNCF 프로젝트 : Open source로서 2024.03.21 현재 CNCF incubating 프로젝트. datadog 등의 특정 업체에게 휘둘릴 일이 없을 뿐 아니라(No Vendor lock-in), 유연성, 상호운용성이 좋다는 뜻. 2023.10 현재 CNCF 프로젝트 중 velocity 2위(1위는 Kubernetes), Linux 재단 프로젝트에서는 3위(1위는 Linux, 2위는 Kubernetes)

4.
주요 Observability 제품 지원: Grafana, Prometheus, Istio 등 Observability (관련) 부문의 주요 Open source 제품 뿐 아니라 Elasticsearch, Datadog, Dynatrace 등 주요 영리 업체도 지원 중이다.
5.
이전 표준 병합: 이전 signal 표준인 OpenTracing과 OpenCensus를 병합. 이들 두 표준의 홈페이지(링크 참조)에 들어가면 모두 OpenTelemetry를 쓰라고 가이드한다.
이외에 아래 글을 읽어볼만 한다. 동일한 주제의 글로 글쓴이는 W3C Trace Context 관련 WG의 멤버이다. 실무의 경험에서 비롯한 듯한 vendor neutrality는 허상이란 주장과 논거가 특히 와닫는다.



참고: Hacker News에서의 OpenTelemetry 평가

•
한줄 요약 - 좋기는 한데 시기상조 (데이터 수집도구인 Vector가 좋음을 논하던 중 Otel에 대한 댓글)

OpenTelemetry란
공식 홈페이지의 정의를 그대로 옮기자면 다음과 같다.
OTel이라고도 하는 OpenTelemetry는 추적, 메트릭, 로그와 같은 원격 분석 데이터를 계측, 생성, 수집, 내보내기 위한 벤더 중립적인 오픈 소스 Observability 프레임워크입니다(출처).
•
Specification: OpenTelemetry API, SDK, 데이터 형태 및 통신에 대한 명세. 2024.03.21 현재 버전은 1.31.0
•
Collector: OpenTelemetry Collector라 불리는 telemetry 데이터 수집기
•
Instrumentation: App에 대한 계측(signal 수집, 전달)을 위한 OpenTelemetry 명세 기반 언어 별 SDK 및 Agent
사용자 관점에서 간단히 보자면, Specification은 signal 설계 시점에, Instrumentation은 데이터 수집, 전달 시점에, 마지막으로 Collector는 전달 위치 지정 시점에 사용된다. 이와 같이 OpenTelmetry는 사실 상 o11y lifecycle 전반에 관여하므로 o11y eco system 설계 시 가장 먼저 고려해야할 요소가 되겠다.
사실 위 3가지 이외에 instrumentation을 구현한 library eco-system이나 Kubernetes Operator, Helm Charts도 OpenTelemetry의 구성요소로 논하나, 이들은 개념적으로 위 3개 요소에 포함되기에 생략했다.
o11y란?
Observability의 줄임말로 Observability의 O와 Y 사이에 11개의 글자를 의미. Kubernetes를 k8s로 부르는 것과 동일.
Architecture
본 글 맨 앞의 그림에 관한 설명이다.
Signal sources
•
App container: k8s pod 내에서 동작하는 각종 workload가 app의 예. 이 경우 app level에서의 signal을 전달할 때 Instrumentation를 사용함으로, Specification에 기반한 telemetry 데이터 생성 및 OpenTelemetry Collector로 전송 가능하다.
•
Infra: OpenTelemetry 명세 기반이 아닌 데이터에 대해서도 능동적으로(pull 방식) 수집한다. 아마도 Kubernetes, Prometheus 등의 특정 유명 제품에 대해서만 그럴 듯. Receivers 참조.
OpenTelemetry Collector
Receivers, Processors, Exporters로 구성되어 각각 signal의 수신, 처리, 수출을 담당하는 pipeline 구조이다. Receiver와 Exporter 각각은 각 Telemetry Data source와 Telemetry Backend에 대응한다. 하나 유의할 점은 이 수집기는 OpenTelemetry 규격 이외의 데이터도 처리 가능하다는 것이다. 상세 내용은 아래 Collector에서 논한다.
Signal Backends
Signal의 최종 종착지. 대표적으로 Metrics의 경우 Prometheus, Logs는 Elasticsearch, Traces에는 Jaeger, Tempo 등이 있다. Elasticsearch Exporter와 같이 해당 제품 전용 프로토콜을 지원하기도 하지만, 근간에는 많은 제품이 OTLP를 직접 지원한다.
Specification

Specification의 API, SDK에 대한 명세는 구현물로 제공되는 Code instrumentation에 대한 것으로, 사용자 관점에서 관심은 사실 상 데이터 형태 및 통신에 대한 명세, 즉 OTLP로 몰린다. OTLP(OpenTelemetry Protocol)는 HTTP 1.1 및 gRPC 상에서 동작함과 동시에 payload를 위한 ProtoBuf 스키마를 정의한다.
아래는 OpenTelemetry 데이터 형태를 간단히 파악하기 위한 metric, log, trace의 OTLP payload 예제이다. 참고로 OTLP는 binary 또는 JSON encoding만을 허용하나, 가독성을 위해 출처에서 YAML 변환 및 일부 데이터를 제거 및 변경 했으며, 마지막으로 아래 이어질 상호연관 설명을 위해 metric에 exemplars field를 추가했다.
Metric 예제
Trace 예제
Log 예제
Metrics, Logs, Traces 간 상호연관
개인적으로 가장 기대했던 부분으로 OpenTelemetry는 metric, log, trace 데이터 간의 상호연관(correlation)을 지원한다. Datadog, Dynatrace 등의 상용 o11y 제품이 상시 내세우는 각 signal view 간 교차 분석 기능에 해당한다.
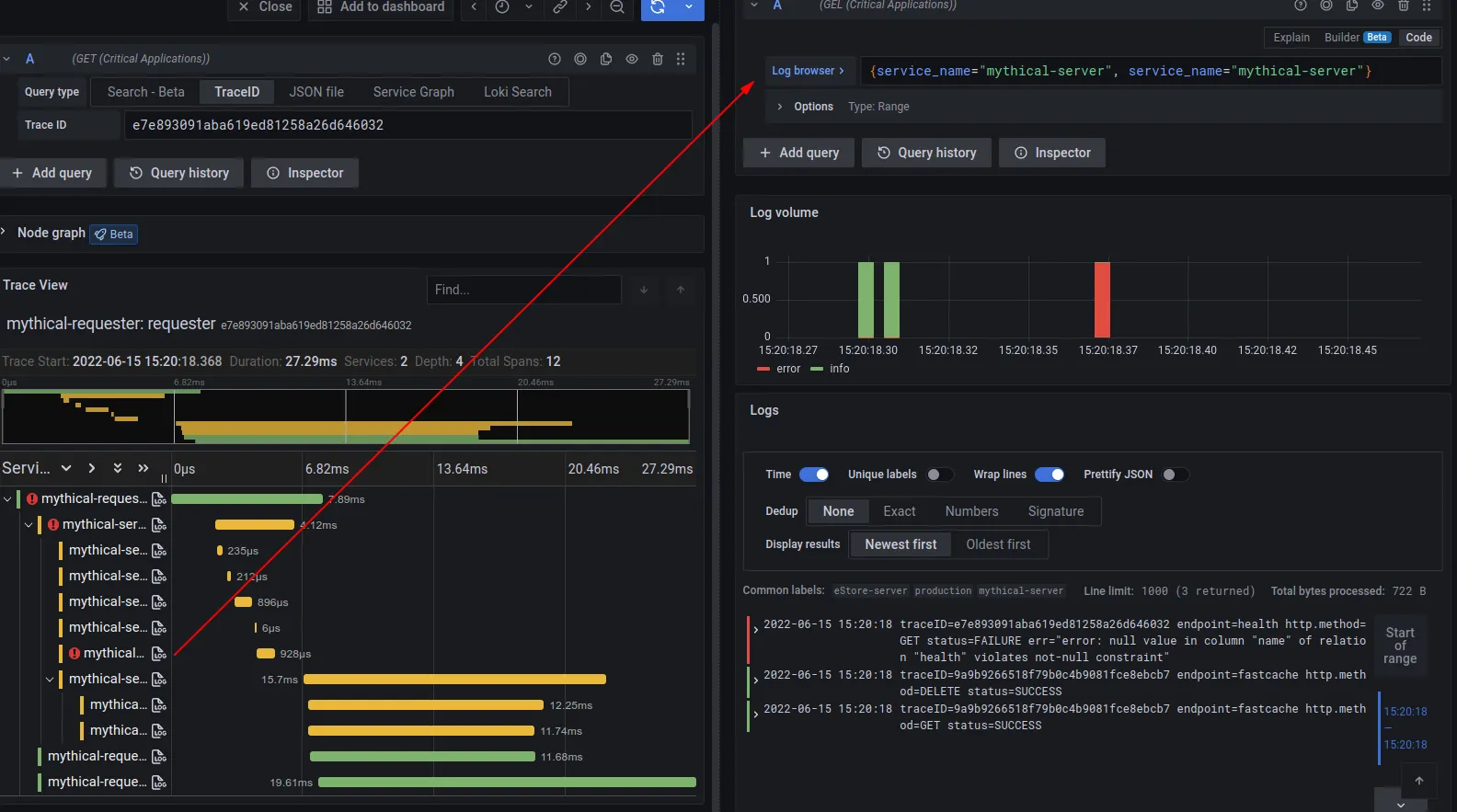
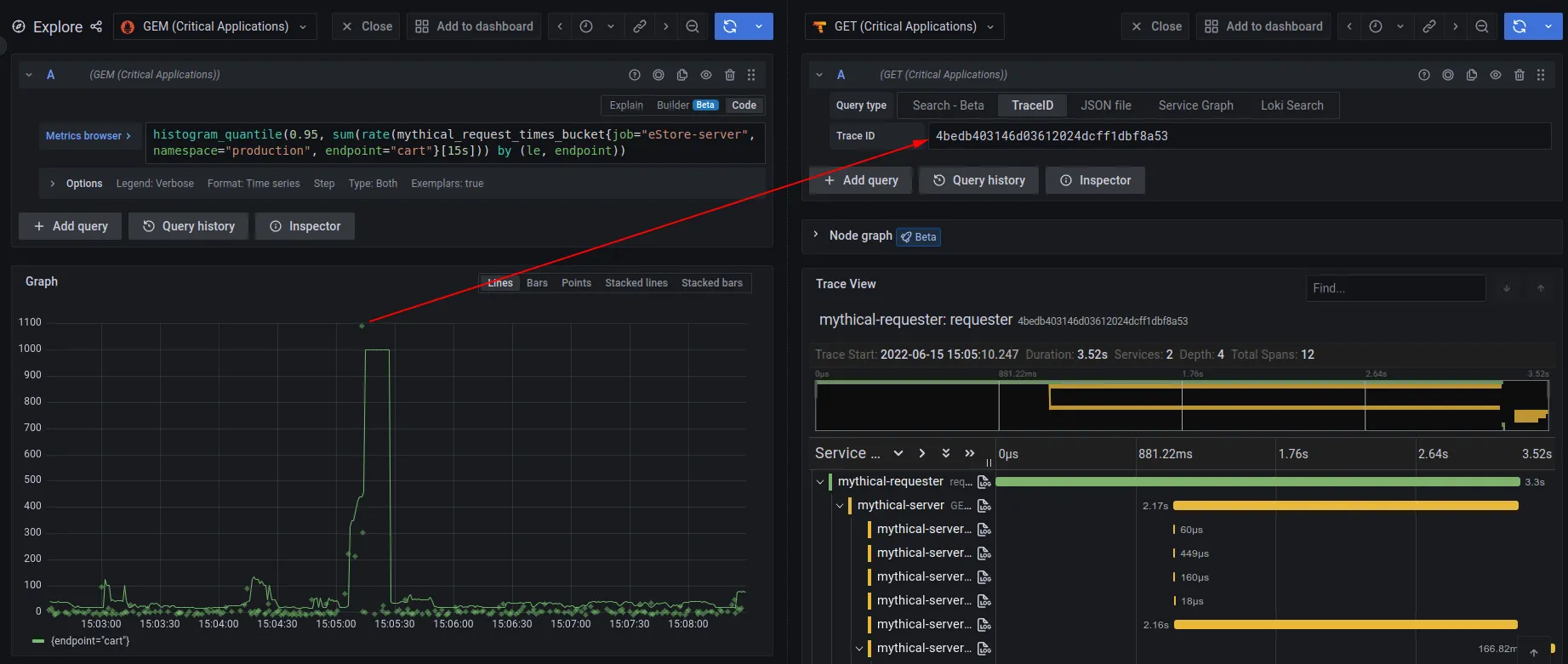
위의 두 그림은 이에 대한 예로, 윗 그림은 trace와 log간 상호연관에 따른 Grafana에서의 활용을 보여준다. 좌측 view에서 trace 데이터 분석 중, 특정 trace, span에 대한 log를 확인하기 위해 우측의 log view를 확인하는 모습이다. 아래 그림은 metric과 trace간의 상호 연관에 해당한다.
OpenTelemetry는 이 상호연관을 위해 세 가지 signal에 공통적으로 traceId, spanId 를 정의한다. 참고로 metric은 옵션으로 들어가는 exemplars field 내에 이들 값을 정의한다(exemplar는 예시 값으로, 예컨데 해당 metric이 sum을 의미할 경우 sum 산출에 사용된 일개 값을 의미한다).
Collector

OpenTelemetry는 OpenTelemetry Collector라 불리는 수집기 구현물을 제공한다. 이는 Receivers, Processors, Exporters로 구성되어 각각 signal의 수신, 처리, 수출을 담당한다. 아래 그림과 같이 Receiver와 Exporter 각각은 각 Signal source와 Signal Backend에 대응하며, Processors는 pipe & filter pattern의 filter에 해당한다.
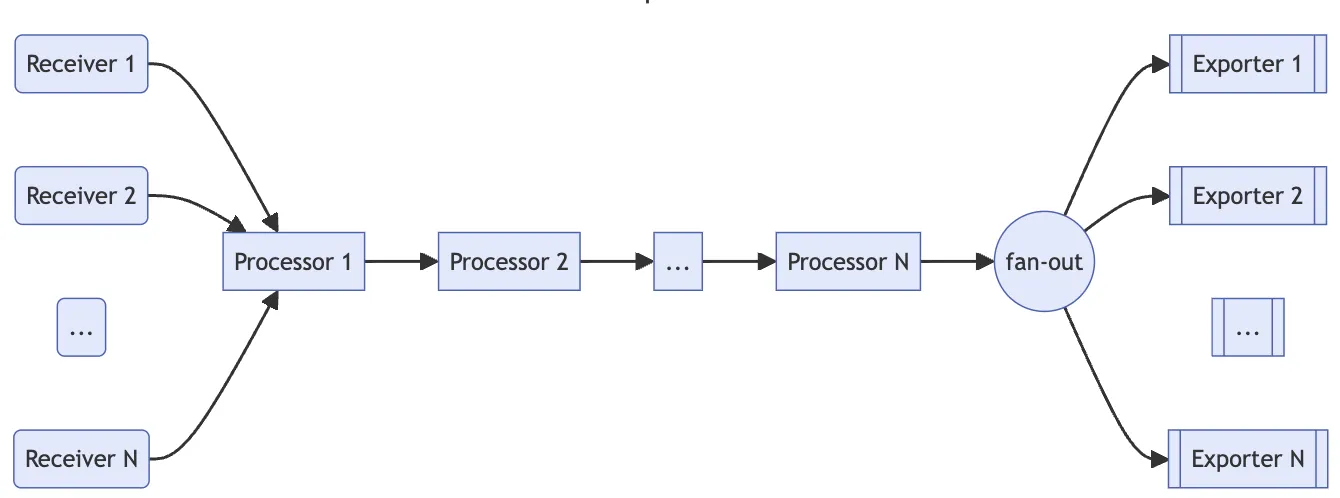
무엇보다 아키텍처 상 OpenTelemetry Collector의 의미는 기존 여러 collectors(e.g. Prometheus exporter, Fluent-bit)를 단일 runtime 형식으로 통합하는 데 있다. 이는 OpenTelemetry 명세를 따르지 않는 데이터에 대해서도 처리 가능하다는 의미이기도 하다.
재미있게도 Kubernetes 상에서 runtime 배포형식은 DaemonSet, Deployment 뿐 아니라 Sidecar에 StatefulSet 마저 지원한다. 이는 수집 대상 성격에 따라 달라진다(참조).
Receivers
OTLP receiver뿐 아니라, Prometheus, Kubernetes 등 주요 data source에 대한 receiver는 기본적으로 포함하며 이외 data source에 대해서는 관련 community에서 custom receiver로 지원한다. 또한 Pull, Push 방식 모두를 사용한다.
공식 문서가 언급하는 Kubernetes 환경 하의 Receiver 목록으로 Kubernetes, app log receiver도 포함되어 있다.

아래는 위에서 언급한 Receiver를 포함하여 community와 vendor가 제공하는 전체 Receiver의 목록이다.

Processors
데이터를 수정(modify)하거나 변환(transform)을 담당하여, 앞선 공식 문서 링크에는 Kubernetes metadata를 application signal에 추가하는 Kubernetes Attributes Processor가 있다. Processor 역시 다양한 processor가 있는데 흥미로운 점은 filter나 transform 과 같은 Processor는 OTTL(OpenTelemetry Tranformation Language)이란 언어를 사용하여 signal에 대한 사실 상 프로그래밍 기반의 변환이 가능하다는 점이다.
아래는 community와 vendor가 제공하는 전체 Processor 목록이다.

Exporters
Backend가 OTLP를 지원할 경우 기본 OTLP Exporter를 통해 직접적으로 데이터를 backend로 전달하지만 Elasticsearch와 같이 OTLP를 지원하지 않을 경우 해당 제품에 특화된 Exporter가 필요하다.
아래는 community와 vendor가 제공하는 전체 Exporter 목록이다.

Instrumentation
앞서 Instrumentation을 OpenTelemetry 명세 기반 언어 별 SDK 및 agent로 칭했는데, SDK와 Agent의 가장 큰 차이는 계측 대상인 App의 명시적 source code 변경 필요 여부이다.
SDK: code-based instrumentation

SDK는 명시적 source code 변경을 통해 OpenTelemetry를 지원하기 위한 것으로 현대에 사용되는 언어 대부분을 지원한다.
Agent: Zero-code / Auto-instrumentation

request/response, database 호출, message queue 호출 등의 app에 특화되지 않은 일반 연산에 대한 instrumentation은 공통 처리가 가능할 것이다(cross cutting concerns). agent가 바로 이를 처리하며 이는 Zero-code 또는 Auto-instrumentation라 불린다.
이를 위해 agent는 해당 로직을 주입(injection)하는데, 구체적인 방법은 언어 별로 달라 bytecode 수정, monkey patching, eBPF 등 다양하게 쓴다.
2024.03.22 현재 지원하는 언어는 .NET, Java, Javascript, PHP, Python, Go로, 특히 Kubernetes 환경의 경우 Operator를 통해 바로 지원 중이다. Kubernetes 상에서의 Injection은 Admission hook과 init container를 사용하는 듯(출처: Java의 경우로 bytecode 수정 기법을 사용).
아래는 eBPF 기반 auto-instrumentation 도구로, HTTP/HTTPS, gRPC의 network 연산에 대해 수행한다고. eBPF 특성 상 bytecode 수정, monkey patching 기법 등의 문제인 code 및 configuration 수정이 없는 것이 장점. 나아가 언어에도 무관한 듯 하다.

Zero-code / auto-instrumentation에 관한 세간(HackerNews) 평가: 쓸만하다.
