
Introduction
대용량 메트릭 운용을 위한 Prometheus 호환 제품 비교로 Thanos, Cortex, VictoriaMetrics, Mimir를 중심으로 다룬다. Prometheus는 대용량 처리를 위해 Federation 아키텍처를 제안하나 여러모로 제한이 있기에, 대규모 메트릭 운용에는 일반적으로 Prometheus 호환의 전담 제품을 사용하는 것으로 이해한다.
참고로, alert 기능은 비교 대상에서 제외하였다. 이는 Alert는 선택에 있어 상대적으로 중요하지 않은 요소란 판단과 함께 비교 요소를 줄이기 위함이기도 하다(개인적으로 Grafana의 alert를 쓰고 있다는 것은 숨겨진 이유  ).
).
).비교 대상 제품


위 링크에 담긴 제품 목록 중 1차 검토를 통과한 제품인 Thanos, Cortex, VictoriaMetrics에 추가로 Mimir를 비교한다. 참고로 위 링크는 제품별 PromQL 호환성 수준 결과로서, PromQL 호환성 수준은 open-source 여부, Github Star 갯수와 함께 1차 검토의 가장 중요한 기준이다.
VictoriaMetrics는 PromQL 호환성이 타 제품이 100%인 반면, 상당히 낮다고 볼 수 있는 74.16%임에도, 높은 Github star 갯수(12.9k)와 단순한 아키텍처, 바이럴이 상당하기에 추가했다. Mimir는 Cortex에서 분가한 프로젝트로서, Cortex의 co-author와 주요 Contributers, 특히 Grafana에서 만든 것이기에 추가했다(metric consumer로서 압도적으로 많이 사용되는 제품은 Grafana이다).
기준에 부합함에도 제외한 제품은 M3인데, Github star 갯수도 상당하고(4.8k), VictoriaMetrics도 역시 타 제품 대비 약점으로 보이는 block storage를 주 저장소로 쓰기에 불공정해보이는 면이 없잖아 있지만, VictoriaMetrics 보다 Github star 갯수가 상당히 적고 아키텍처가 복잡해보인다는 점이 컸다.
이외에 Promscale은 RDB 기반으로 동작하여 PromQL과 SQL 모두를 지원하는 독특한 구조라 함께 다룰만해보이기도 하지만, 문제는 Github star 갯수가 1.3k로 적고 무엇보다도 현재 deprecated되었다고.
Architecture 관점 비교
아래 그림은 최좌측 metric source에서 생성된 metric이 최우측 metric consumer에서 소비되기까지의 과정을 나타낸다. Cortex와 Mimir는 푸른색으로 함께 다루었는데, Mimir는 Cortex에서 분가한 프로젝트이기에 아키텍처 관점에서는 동일하기 때문이다. 초록색은 VictoriaMetrics, 붉은색은 Thanos, 보라색은 Thanos, Cortex, Mimir 공통 컴포넌트에 해당한다.
이외에 앞서 말했듯 alert 관련 component는 제외했다(나아가 alert는 아키텍처 상 read path에 있는 타 컴포넌트와 구조가 동일하거나 더 단순하기에 생략해도 크게 문제될 게 없어 보인다).
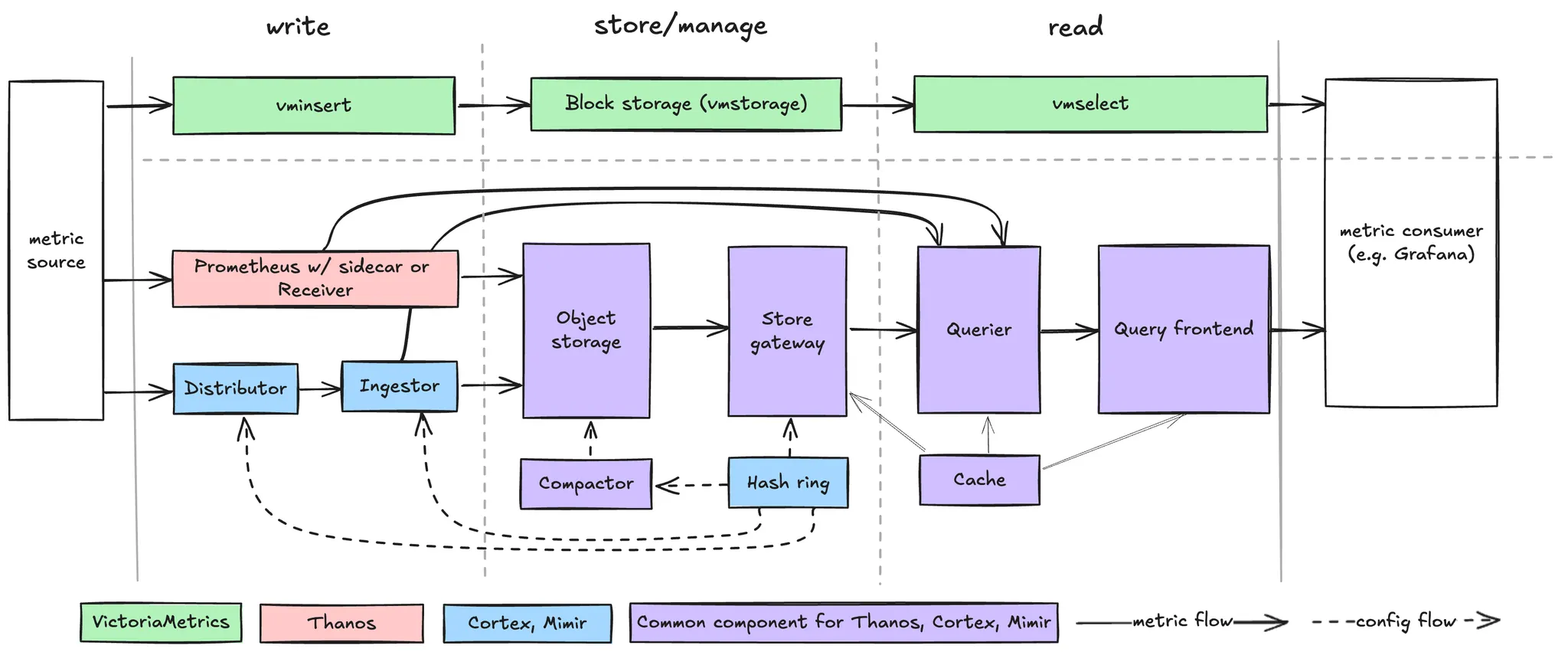
VictoriaMetrics, Thanos, Cortex, Mimir의 아키텍처 관점 비교
일단 4개 제품 모두 소위 ‘마이크로서비스’ 또는 ‘클러스터’ 모드라 하여 각 컴포넌트 별로 독립적으로 배포 및 확장이 가능하다. 예컨데 조회를 담당하는 모듈인 vmselect, Querier, Query frontend 모두 타 컴포넌트에 관계없이 상황에 따라 인스턴스 수를 늘리거나 줄일 수 있다. 컴포넌트가 많다고 해서 겁먹을 필요가 없다는 뜻.
각 컴포넌트 설명에는 stateful, stateless, external , internal 의 네 가지 태그 중 하나를 달았다. external 은 외부 솔루션을 의미하고, internal 은 타 컴포넌트 내 내장된 요소를 의미한다.
VictoriaMetrics (초록색)

쓰기(vmsinsert), 저장(vmstorage), 읽기(vmselect) 역할로 나뉜 3개 컴포넌트가 전부인 매우 직관적인 아키텍처이다. Block storage를 사용한다는 점만 제외하면 관리용이성 측면에서는 최상이다. vmstorage 는 stateful 이고 나머지는 stateless 이다.
문제는 저장을 담당하는 vmstorage 가 타 제품 대비 block storage 이란 점이다. block storage는 object storage 대비 고성능이긴 하지만 고비용에 내구성, 확장성, 탄력성 등 대용량 처리 측면에서 많은 단점을 가진다. 이외에 rebalancing과 node draining에 이슈가 있다고 하는데 이는 Cortex/Mimir와는 달리 Hash ring을 운용하지 않기에 수작업이 요구되는 부분을 의미하는 듯하다. Hash ring 미장착은 아키텍처 단순성을 더 중요하게 둔 전략적 선택으로 보인다.
Thanos, Cortex, Mimir 공통 (보라색)
일단 이들 제품은 VictoriaMetrics 대비 컴포넌트 수가 매우 많다. 그만큼 관리가 어렵다는 뜻. 다만 컴포넌트 별 독립적 배포/확장과 컴포넌트 내 인스턴스 간 share nothing은 VictoriaMetrics의 그것과 동일함과 동시에 object storage를 사용한다는 장점을 가진다.
•
Object Storage: external 앞서 논했듯, 대용량 데이터에는 다양한 측면에서 block storage보다 유리하다. AWS S3 등 외부 제품을 사용한다.
•
Compactor: stateless 일종의 Object Storage block 관리자로서, 블록의 병합, 중복 제거, 사용되지 않는 블록 삭제 및 버킷 인덱스를 최신 상태로 유지한다고.
•
Store Gateway: stateful Object Storage에서 block을 쿼리하는 용도로, 실시간 쿼리에 대한 대응을 위해 bucket index를 주기적으로 다운로드하여 bucket view를 업데이트한다고. stateful 인 이유는 이 index, chunk, metadata에 대한 local disk로의 caching 목적으로 보인다(별도 cache layer가 있음에도 불구하고).
•
Querier: stateless PromQL 표현식을 처리하는 주체. 장기 데이터는 Store Gateway로부터, 최근 데이터는 Receiver/Prometheus-sidecar(Thanos의 경우), Ingester(Cortex, Mimir)로부터 가져온다.
•
Query frontend: stateless query 성능을 높이기 위한 optional component이다. query를 sub query로 나누어 sub query 결과를 병합 및 반환하는 역할로 보인다. sub query 결과는 Querier 뿐 아니라 cache에서도 얻을 것이다.
•
Cache: external 세 제품 모두 주로 memcached를 사용하는 듯. Cortex와 Mimir는 Thanos보다 Cache를 더 많이 사용하는 듯하다. cache 대상은 index, chunk, metadata 등이다.
Thanos (붉은색)


Thanos는 기본적으로 Prometheus 운용 환경에서 확장하는 시나리오에서 출발한 듯 하다. Sidecar란 모듈은 이름에서도 보이듯 Prometheus에 붙어 동작하기 때문이다. 이 말인 즉슨, Thanos 운용 시 Prometheus도 필요하다는 뜻인데, 신규 설치 시나리오에서는 오히려 단점이 된다. 이를 의식한 것인지, Prometheus-sidecar를 대체하는 Receiver란 컴포넌트가 추가되었으며, Receiver는 scrapping 방식이 아닌 remote write API 기반으로 metric source와 연동한다.
어쨌건 Architecture 관점에서 Prometheus-sidecar 또는 Receiver는 metric 수집 및 Object Storage로 저장 역할을 담당한다. Querier로의 최근 데이터 제공 역할은 임시 저장 데이터를 활용하는 아이디어에서 출발한 것이 아닐까 싶다.
WAL(Write Ahead Log)이 사용되기에 당연스럽게 stateful 구성이다.
Cortex, Mimir (푸른색)




Cortex, Mimir는 Thanos보다도 Component 종류가 많다.
•
Distributor: stateless metric source로부터 time-series data 수신 및 해당 data를 validation, 다수의 batch로 분할 및 Ingester로의 전송, 그리고 (고가용성을 위한) replication 생성 목적이라고.
•
Ingestor: stateful Object storage로의 저장 및 Querier를 위한 최신 데이터 제공 목적이라고. stateful 인 이유는 WAL(Write Ahead Log)와 WBL(Write Behind Log; Mimir의 경우)의 존재 때문으로 보인다.
•
Hash ring: internal key-value(KV) store로 구현된다. Thanos와 VictoriaMetrics에는 본 컴포넌트가 없는데, 클러스터 관리 측면에서는 의존성 및 관리 포인트 증가하는 약점이지만, 그만큼 load balancing 효과가 더 클 것으로 예상되고, VictoriaMetrics에서 논했던 rebalancing과 node draining 이슈를 포함한 고가용성 및 Scalability 이슈 처리 측면에서 유리할 듯 보인다.
2025.02.12 업데이트
Mimir는 Hash ring용으로 etcd 등의 외부 솔루션을 포함한 여러 옵션을 제공하나 default는 Memberlist란 Go library 기반으로 타 컴포넌트 instance 내부에 내장 및 편재된다고. Instance간 데이터 공유 및 동기화(편재)는 Gossip protocol을 사용한다. 당연스럽게도 default 옵션이 가장 좋아 보인다.


•
Query Scheduler: stateless optional 컴포넌트로 위 아키텍처 그림에는 없다. 이를 안쓰면 Query frontend 스케일링에 제한이 걸린다고.
Architecture 관점 비교 결과
무엇이 더 났다고 말하기 어렵다. 복잡도 관점에서는 VictoriaMetrics > Thanos > Cortex/Mimir 이지만, 반대로 높은 아키텍처 복잡도가 더 많은 feature를 의미할 수도 있기 때문이다. 이들 feature 중 눈에 띄는 부분은 object storage 및 hash ring로서, Cortex/Mimir는 이들 둘 모두를 사용하는 반면, Thanos는 object storage만, 그리고 VictoriaMetrics는 이들 두가지 모두를 사용하지 않는다. 이들에 대한 장단점은 앞서 논했다.
Architecture 외 one on one 비교
Architecture 외 측면을 중심으로 제품 간 1:1 비교하여 승자를 나머지와 하나씩 비교하는 것으로 최종 선정을 논한다. 앞선 비교에서는 Cortex와 Mimir를 구분짓지 않았는데, 여기서부터 시작한다. 결론부터 이야기하자면 Mimir가 최종 승자이다.
Cortex vs Mimir


Cortex와 Mimir 비교는 위 글로 대신한다. Mimir가 더 났다는 점을 논하는데, Grafana 측 글이라 편향성을 당연히 고려해야 함에도 더 이상의 비교를 무의미하게 만든다.
Mimir 뿐 아니라 Cortex가 어떻게 만들어지게 되었는지, 그리고 feature 측면에서 어떻게 차이나는지를 무려 Cortex, Mimir의 co-author (not contributor)가 논한다(Cortex의 또다른 co-author는 Prometheus의 Julius Volz라고!). 뿐만 아니라 Cortex, Mimir의 주요 contributor가 죄다 Grafana 인원에 Cortex 기여의 87%를 Grafana에서 이루었다고.

Grafana Nixes Cortex Support for Amazon Managed Prometheus
Grafana Labs has made some changes to its Prometheus support during the past few weeks as it nixes support for Cortex and introduces Mimir in its place.
https://thenewstack.io/grafana-nixes-cortex-support-for-amazon-managed-prometheus/

Cortex를 사용하는 AMP에 대한 Grafana의 지원이 중단될 것이란 기사. Elasticsearch 라이센스 사태를 고려한 대응에 대해서도 논한다.
VictoriaMetrics vs Mimir
여기서도 Mimir의 손을 드는데, VictoriaMetrics가 Mimir보다 나은 성능을 보인다는 리포트와 이에 대한 긍정적 논의, 그리고 여러 호평이 보임에도 불구하고, PromQL의 낮은 호환성, 그리고 object storage가 주 저장소가 아닌 점이 가장 큰 이유다. 이외에 이 바닥의 주된 논의는 Thanos, Cortex/Mimir 사이에서 일어나며, VictoriaMetrics는 마치 ‘나도 있어요!’ 하고 외치는 느낌이 크다.
Grafana Mimir – Horizontally scalable long-term storage for Prometheus | Hacker News
*EDIT*: I see from another reply there is a basic comparison to Cortex here: https://grafana.com/blog/2022/03/30/announcing-grafana-mimir... To the Mimir folks, I'd love to see something similar Mimir v. Thanos.

https://news.ycombinator.com/item?id=30854734
무려 Cortex/Mimir, VictoriaMetrics author가 참전한 Thanos, Cortex, Mimir + VictoriaMetrics 비교 논의. 제목이 Mimir이므로 VictoriaMetrics가 곁다리가 된 측면도 있다.
[Question] I am a cortex user. which one should I choose between victoriametric and mimir?
Both projects are interesting. I like mimir in terms of being closer to the standard, but I feel like victoriametric is less resource intensive. (Is…

https://www.reddit.com/r/PrometheusMonitoring/comments/12tuwe8/question_i_am_a_cortex_user_which_one_should_i/
VictoriaMetrics vs Mimir의 또다른 논의. 여기에도 Tom Wilkie가 참전 중이다.
Thanos vs Mimir
Thanos는 Mimir 대비 Github star도 훨씬 많고(13.2k vs 4.2k), 이 바닥 논의는 주로 Thanos가 중심에 있고 타 제품은 이에 비교되는 상황이다. 그럼에도 여전히 Mimir의 손을 들고 싶은데, Thanos에 못지 않은 바이럴, 사실 상 독점적 Metric consumer인 Grafana와의 유착(!) 관계와 Prometheus 확장에서 진화해온 Thanos보다 처음부터 대용량을 고려해서 새롭게 만들어진 시스템이란 측면이 크다.
이외에 VictoriaMetrics vs Mimir 내 Hacker News의 비교 논의에서 Mimir co-author인 Tom Wilkie의 Thanos 언급 부분도 한 영향했고(사실 기술적 판단보다는 그의 권위(?)와 광고에 눌린 측면이 더 클 듯 ).
). 검토 중 눈에 띈 Mimir 기타 특징
1.
고품질 documentation: 위 비교 시 각 제품의 공식 문서를 전반으로 참고하면서 느낀 점 중 하나로 Mimir가 documentation 수준이 가장 좋다는 것이었다. 그 다음으로 VictoriaMetrics였고.
2.
초기 설계 시점부터 고려된 Multi Tenancy: 비교한 시스템 모두가 multi tenancy를 지원하지만, Mimir는 이를 초기 설계 때부터 고려했다고. 이로 인해 타 제품 대비 어떤 점이 더 뛰어난지는 구체적으로는 확인 못했는데 아마도 격리 수준에 관한 무엇이 아닐까 예상해본다. 참고로, 다수의 조직이 독립적으로 metric backend가 필요로 하지 않더라도, 최소 3개 환경(development, stage, production)으로 운영되는 일반적 상황을 고려하자면, multi tenancy는 상당히 유용한 feature이다.
3.
Monolithic 배포 모드 지원: 많은 컴포넌트는 약점 중 하나인데, 이들 컴포넌트를 단일 프로세스로 구성하는 Monolithic 모드도 지원한다. 공식 문서는 본 모드로 수평 확장까지 지원함을 논하는데, 본 모드로 production 운영이 가능할지는 확인이 필요해보인다(Hash ring을 어떻게 다루는지 등).


4.
Tempo, Loki 등 운용 시, knowlege base 재사용 효과: Tempo, Loki 아키텍처는 metric이 아닌 trace, log를 다룬다는 점만 다를 뿐 사실 상 Mimir의 그것과 매우 유사하다. Object storage를 storage 근간으로 쓸 뿐 아니라 컴포넌트 종류, 이름마저 동일하다(Distributer, Ingester, Compactor, Querier, Query Frontend 등). 아마도 Mimir, Tempo, Loki 모두 Grafana에서 만든 것을 고려한다면 코드와 feature 상당 부분이 동일하거나 유사하지 않을까 싶다. Loki의 경우는 데이터 모델마저 Prometheus의 그것과 판박이다.

Loki의 Data model. value에 부동소수점이 아닌 문자열이 위치한다는 점만 빼면 Prometheus의 data model과 똑같다. 출처: Loki architecture
Appendix 1: Prometheus Federation에 대하여
Prometheus Federation은 Prometheus 자체의 대용량 솔루션으로 구조는 매우 간단하다.
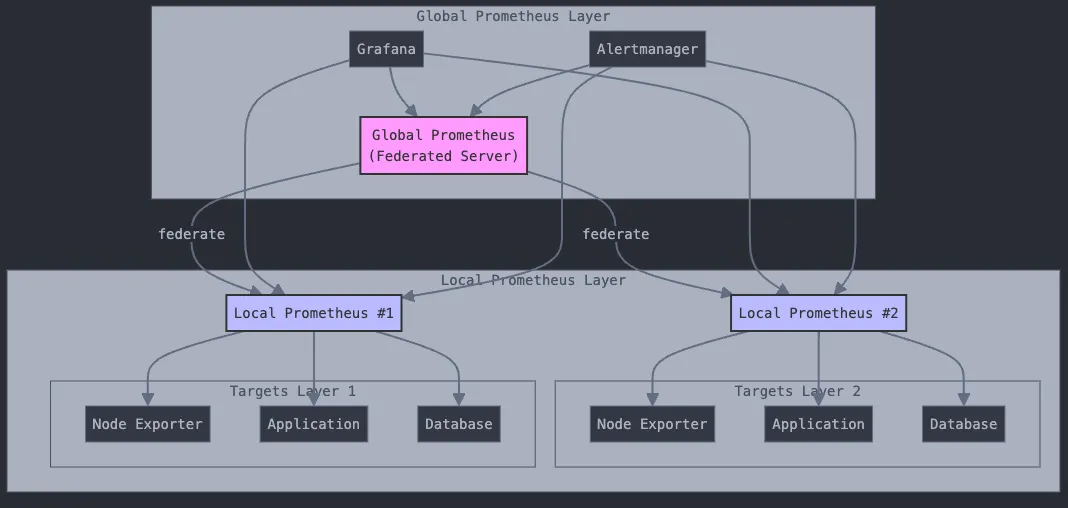
Claude AI를 사용하여 그린 Prometheus Federation 구조
Local layer에서는 여러 Prometheus가 metric source(target)에서 분담 수집하고, global layer에서 local layer의 여러 Prometheus에서 down sampling한 metric을 수집, 운용하는 구조이다.
하지만 이 구조는 metric consumer가 다수의 Prometheus로 접근해야 하고(특히 비 down sampling된 metric 조회 시), HA를 위해 매 Prometheus 인스턴스마다 이중화를 해야하는 큰 단점을 지닌다. object storage는 물론 사용되지 않는다.
무엇보다 Prometheus author인 Julius Volz가 Mimir의 Tom Wilkie와 Cortex의 co-author란 점은 이 구조에 한계가 있음을 이들이 고백한 꼴이 아닌가 싶다. 뭐 땜시 동일 목적의 제품을 새로 만들었겠는가.
Appendix 2: Mimir와 AMP의 운용 비용 차이에 관하여
본 방법으로 해당 860K/s 인입률에서의 비용 측정 결과, 약 85% 정도 AMP보다 Mimir가 더 저렴하다는 결과가 나왔다(상세 내용은 의도적으로 누락했다). 참고로, AMP가 PaaS 제품임을 감안하자면 인입률이 작을 수록 비용 차이가 작을 것이고, 클 수록 더욱 커질 것이다.