
Introduction
Kubernetes 내 Metric, Logs, Traces(MLT) pipelines를 OpenTelemetry Collector로 교체하는 방법, 특히 각 signal 관점에서 어떻게 OpenTelemetry Collector workload를 나눌지에 대해 논한다.
 OpenTelemetry의 사용자 관점 Overview, OpenTelemetry 설치 준비: Operator 설치, OpenTelemetry Collector로 Prometheus (scraper) 교체하기 의 연장선 상에 위치한 OpenTelemetry Collector의 상세 검토 중 하나이다.
OpenTelemetry의 사용자 관점 Overview, OpenTelemetry 설치 준비: Operator 설치, OpenTelemetry Collector로 Prometheus (scraper) 교체하기 의 연장선 상에 위치한 OpenTelemetry Collector의 상세 검토 중 하나이다.예제 코드는 버전으로 따지면 alpha 수준으로 글과 함께 지속 업데이트 예정이다. 완료 시 본 callout은 제거 예정이다.
Motivation
OpenTelemetry Collector는 일반적으로 보이는 아키텍처 그림이 암시하는 듯한 단일 workload의 아키텍처와는 달리 다수의 workload로 나누어야 하는데, 이는 무엇보다 OTel receiver, 즉 signal 종류가 workload 형식, 즉 배포 패턴(e.g. Deployment, DaemonSet)을 사실 상 규정하기 때문이다. 그렇다고 receiver 종류 별로 workload를 나누기에는 그 종류가 너무도 많다. 결국에는 이들에 대한 분류가 요구된다.
조직 관점 분류 방법에 대하여
운영 조직 관점으로도 나누는 것을 고려해볼 수 있지만, signal 자체가 운영 조직 별 분리를 반영하기 어려운 경우가 더 많을 뿐 아니라 OpenTelemetry 이전의 pipeline에서도 이와 같은 분리를 찾기는 어려울 듯 예상된다.
일반적인 OTel Collector 운용 아키텍처
일반적으로는 (Kubernetes 환경의 경우) DaemonSet (agent 모드)로 collector를 두어 각 노드에 해당하는 모든 signal을 수집하고, 수집된 모든 signal을 gateway 모드(e.g. Deployment)의 단일 collector로 보내는 아키텍처를 사용하는 듯 보이며, 특히 아래 OpenTelemetry 서적은 이를 가장 좋은 아키텍처로 논한다. 좋은 이유로 agent와 gateway 모드의 장점 모두를 취할 있음과 동시에 데이터에 대한 유연성과 이식성을 갖추는 것을 꼽고 있다.

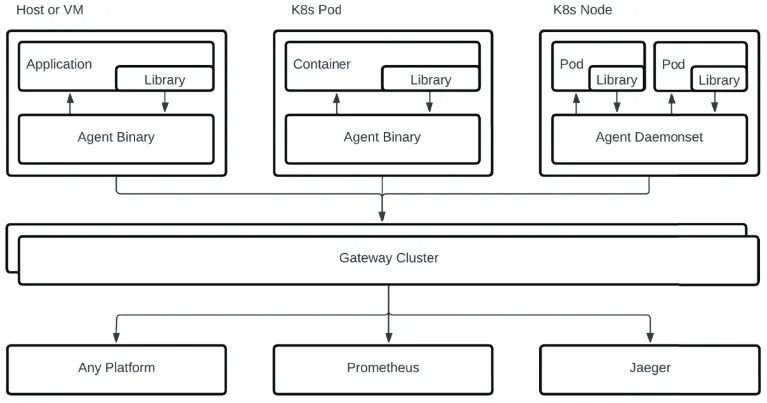
에 담긴 agent + gateway 모드의 OpenTelemetry Collector 운용 아키텍처. DaemonSet 으로 각 노드에서 signal을 수집하고 gateway 모드의 collector에서 이를 모아 observability backend로 보내는 모습이다.
하지만, DaemonSet 은 모든 node에 collector instance가 위치하기에 관리 point가 늘어난다는 점과 HA(High Availability) 구성이 안된다는 점이 큰 약점이다. 아래에도 논하지만 물론 file log나 host metric 수집 시에는 이 배포 형태가 유의미함과 동시에 필수이지만, 이외의 경우까지 굳이 이 배포 형태를 고집할 이유가 없어 보인다.
실제 위 책에서는 소위 Collector Per Signal이란 표현으로 signal 별로 collector를 나누는 아키텍처를 ‘Advanced Scenario’로 논하며, 책임 격리와 noisy neighbor 문제를 해결을 장점으로 논한다. 아래 분류는 사실 상 이 Advanced Scenario에 해당한다.
node 별로 수집되는 signal, 특히 file log까지 수집 대상에 포함된다면, 굳이 아래와 같이 signal 별로 나눌 필요 없이 상기 agent + gateway 모드로 운용하는 것이 유리해 보인다. 무엇보다 아키텍처가 단순해지기 때문이다.
이 경우 아래 분류의 mapping diagram에서는 Node Collector가 Prometheus, OTLP collector의 역할을 겸하게 되고, observablity backends로의 signal 전달 전용의 gateway collector가 추가되겠다.
Collectors
다행히도 receiver 이외에 타 OpenTelemetry component는 workload 형식에 대한 제한이 없다. 또한 유지보수성을 고려하자면 workload는 적을 수록 좋다. 따라서 최소 workload 분류 단위인 workload 형식 별로 나누는 것을 고려한다. 참고로, OpenTelemetry Collector는 Deployment, DaemonSet, StatefulSet 이외에도 sidecar 형식의 배포 패턴으로 지원한다(공식 문서는 DaemonSet과 sidecar를 Agent로, 이외를 Gateway로 표현하며 receiver 수준에서야 구체적인 형식을 논한다).
아래는 위 관점에 따라 분류한 결과(우측)와 각각에 해당하는 OpenTelemetry 사용 전의 MLT 수집기를 나타낸다. 실선은 OTel 적용 전에도 사용되는 signal에 대한 관계를, 점선은 OTel 적용 후에 추가 가능한 경우를 나타낸다. 참고로 trace의 경우 OTel 전에는 Trace backend로 signal을 직접 보내는 것이 일반적이라 예상된다.
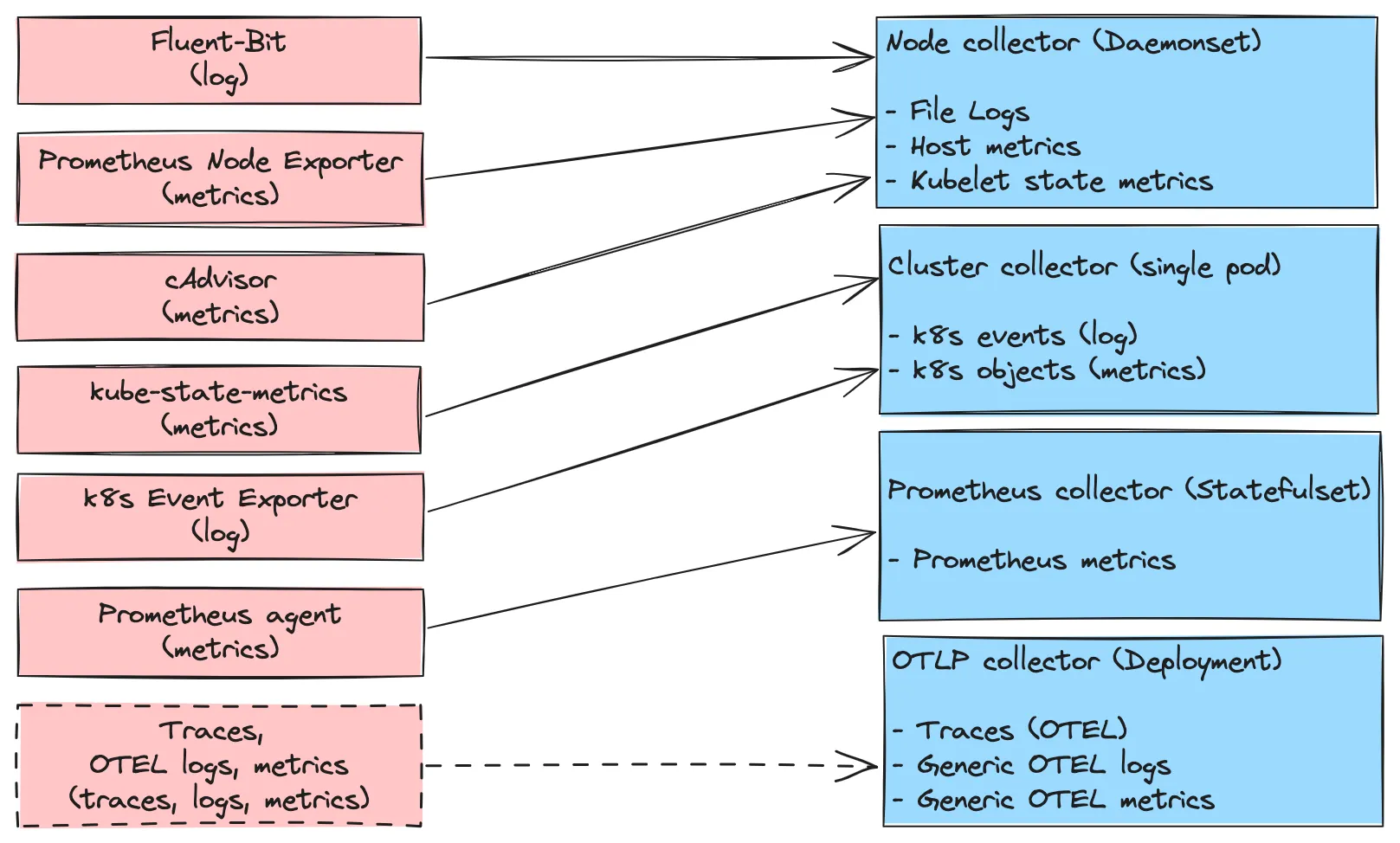
OpenTelemetry Collector 적용 전 components와 적용 후의 collectors 간 관계. Collector 명칭은 직관성을 위해 workload 형식이 아닌 signal의 공통 속성에서 추출했다.
보다시피 OpenTelemetry Collector의 사용 결과, MLT에 대한 일관된 관리의 장점 뿐 아니라 최소 7개의 workload를 4개로 줄일 수 있다(물론, workload 별 부하는 더욱 커질 것이므로 이에 대한 적절한 resource 추가 할당이 필요하겠다).
아래 각 Collector에 대한 설명과 예제 코드로, 해당 collector가 담당하는 각 signal의 종류를 log, metric, trace 로 표현했다. Signal backends로는 Prometheus, Elasticsearch, Jaeger를 상정했다.
Node Collector
공식 문서에서 DaemonSet 을 권장하는 receiver가 모인 collector이다.
log | Filelog
수집 대상은 stdout/stderr로 생성된 Kubernetes, apps log으로, 사실 상 Fluentbit를 대체한다. 이를 위해 log scraping 및 전달 뿐 아니라 Processors 에서 언급한 다양한 processor 사용을 고려해야 한다.
•
•
metric | Kubelet Stats
node, pod, container, volume, filesystem network I/O and error metrics 등 CPU, memory 등 infra resource에 관한 metric을 다루어, 각 노드의 kubelet이 노출하는 API에서 추출한다. 사실 상 cAdvisor의 대체이다.
•
•
metric | Host Metrics
수집 대상은 node (cpu, disk, CPU load, filesystem, memory, network, paging, process..)의 metric으로, 사실 상 Prometheus Node Exporter를 대체한다. Kubelet Stats Receiver와 일부 항목이 겹치므로 동시 운용 시 중복 처리가 필요하다.
•
•
예제 코드(Filelog , Host Metrics 미완료)
Cluster Collector
단일 replica 사용 권장인 receivers 대상으로, 이들 receiver는 2개 이상의 instance 사용 시 중복이 발생 가능하기 때문이라고 공식 문서에서 논한다. 두 receiver 모두 cluster 관점에서 추출하기 때문이라고. 이에 따라 deployment type에 1개의 replica로 설정한다.
log | Kubernetes Objects
주로 Kubernetes event 수집용으로 Kubernetes API server 출처의 objects(전체 목록은 kubectl api-resources 로 확인) 수집에도 사용한다.
•
•
metric | Kubernetes Cluster
•
•
예제 코드
Prometheus Collector
Istio를 포함한 기존 동적 Prometheus metric scraping이 설정된 metric 대상의 collector이다. 이에 대해서는OpenTelemetry Collector로 Prometheus (scraper) 교체하기 에서 자세히 다룬다.
OpenTelemetry Collector로 Prometheus (scraper) 교체하기 에서 자세히 다룬다.OTLP Collector
공용 receiver, exporter 공통적으로 otlp 프로토콜을 사용하고 replica 개수 제약이 없는 signal 대상 collector로서, 제약이 없을 경우 가장 운용에 유리한 배포 패턴인 Deployment 를 사용한다. MLT 모두를 대상으로 한다.
trace | Generic OTEL trace
•
•
metric | Generic OTEL metric
앞서 논한 metric 이외의 app level metrics 등의 여타 metric 수집을 위한 endpoint이다.
•
•
log | Generic OTEL log
Istio의 OTel access log를 포함한 여타 log 수집을 위한 endpoint이다.
•
•