
Introduction
Open source를 기반으로 한 Observability 환경 구축에 대한 논의이다. 본 논의 중심에는 OpenTelemetry 뿐 아니라 Service Mesh(Istio), Prometheus, Grafana가 위치한다.
Motivation
일반적으로 Observability의 vendor 제품 운용 비용은 상당하며, 이로 인한 제약은 커지기 마련이다. 다음은 Hacker news에 올라온 Coinbase의 Datadog 비용 이슈(연간 $65M, 약 867억원)에 대한 논의인데, 성토가 어마어마하다.

상기 논의의 주요 comment 모음(한글 자동 번역)
위 Coinbase는 결국 전담 팀을 꾸려 Open Source 기반으로 전환 중에 Datadog이 ‘거부할 수 없는 거래’를 제시해 Datadog으로 유지했다고. Observability는 사실 상 infra level의 서비스로 app 전반의 영역에 걸쳐 분포하기 마련이라 타 솔루션으로의 전환이 어려울 것은 자명하다.
이런 상황에, OpenTelemetry로의 data export를 못하도록 OTel Datadog receiver PR을 방해한 흔적마저 보인다. 이를 딛고 감행한 해당 PR 작성자로의 응원이 엄청나다.

Summary
•
Open source 기반 Observability는 vendor의 그것을 대체 가능하다(솔직히 훨 났다  ).
).
).•
본 Open source 기반 Observability Architecture에는 OpenTelemetry 및 Istio, Prometheus, Grafana가 중심이다. 이들 모두 각자의 영역에서 오랜 시간 검증 받은 제품이다.
•
Observability는 각 환경에 맞게 특화 요구가 크기 마련이고 이는 제품의 Extensibility, Customizability에 대한 요구로 이어진다. Open source는 이를 더욱 잘 처리한다.
•
Correlation 분석 역시 가능하다. OpenTelemetry 및 Grafana 덕분이다.
•
아키텍처가 단순해진다. 단일 모듈 내에 Observability를 포함한 다수의 주요 횡단 관심을 넣을 수 있기 때문이다. Istio 덕분이다. 타 아키텍처 대비 비교 우위점 참조.
Telemetry 별 구축 전략
OpenTelemetry가 MLT(Metric, Log, Trace) 모두를 지원하지만, 이를 무작정 일괄 적용하는 것은 쉽지 않을 뿐더러 legacy 고려 필요 시 비 효율적이다. 다음은 각 telemetry 별 적용 전략이다.
•
Metrics: Prometheus(OpenMetrics) 규격 사용은 필수. Istio를 포함하여 이미 Metric 관련 주요 제품은 본 규격을 따르기 때문이다. OpenTelemetry의 metric 규격을 따르는 제품은 당췌 보이지 않는다. 그리고 OpenTelemetry Collector는 Prometheus 규격을 receiver, exporter 모두에서 지원한다.
•
Logs: 신규 구축은 환경에 따라 선택적으로 OpenTelemetry 규격을 도입한다. legacy log format 전환은 쉽지 않을 뿐 아니라(해당 format에 의존한 시스템이 많기 마련이기에) 전환 비용 대비 효과성이 크지 않기 때문. 다만 legacy 사용 시 traceID를 포함하도록 변경해야 correlation 분석이 가능하다.
•
Traces: OpenTelemetry 규격을 그대로 사용한다. Trace 관련 주요 제품 대부분이 OpenTelemetry를 지원한다. Legacy 전환이 필요할 경우는 OpenTelemetry Collector 적용부터 진행한다(Zipkin, Jaeger 등의 주요 trace protocol에 대한 receiver를 지원한다).
Architecture & details
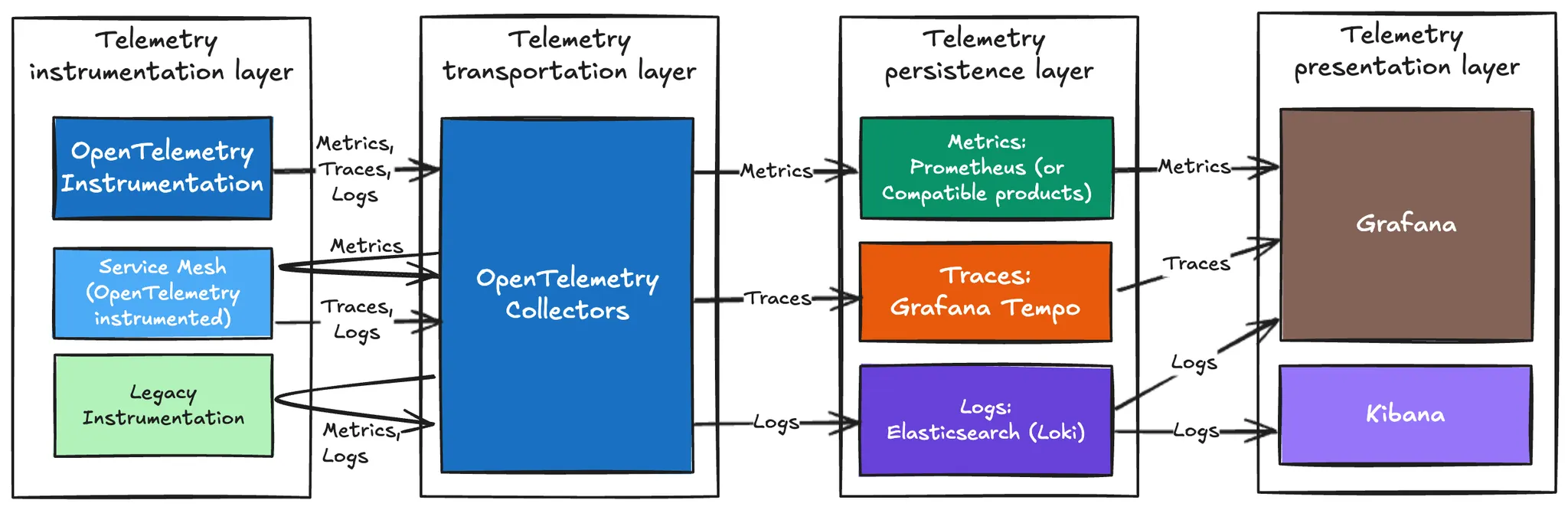
본 글 맨 앞에 위치한 Open source 기반 Observability architecture 그림에 대한 상세 설명이다. Telemetry의 lifecycle을 따라 계측(instrumentation), 전송(transportation), 저장(persistence), 조회(presentation)으로 계층을 나누었다.
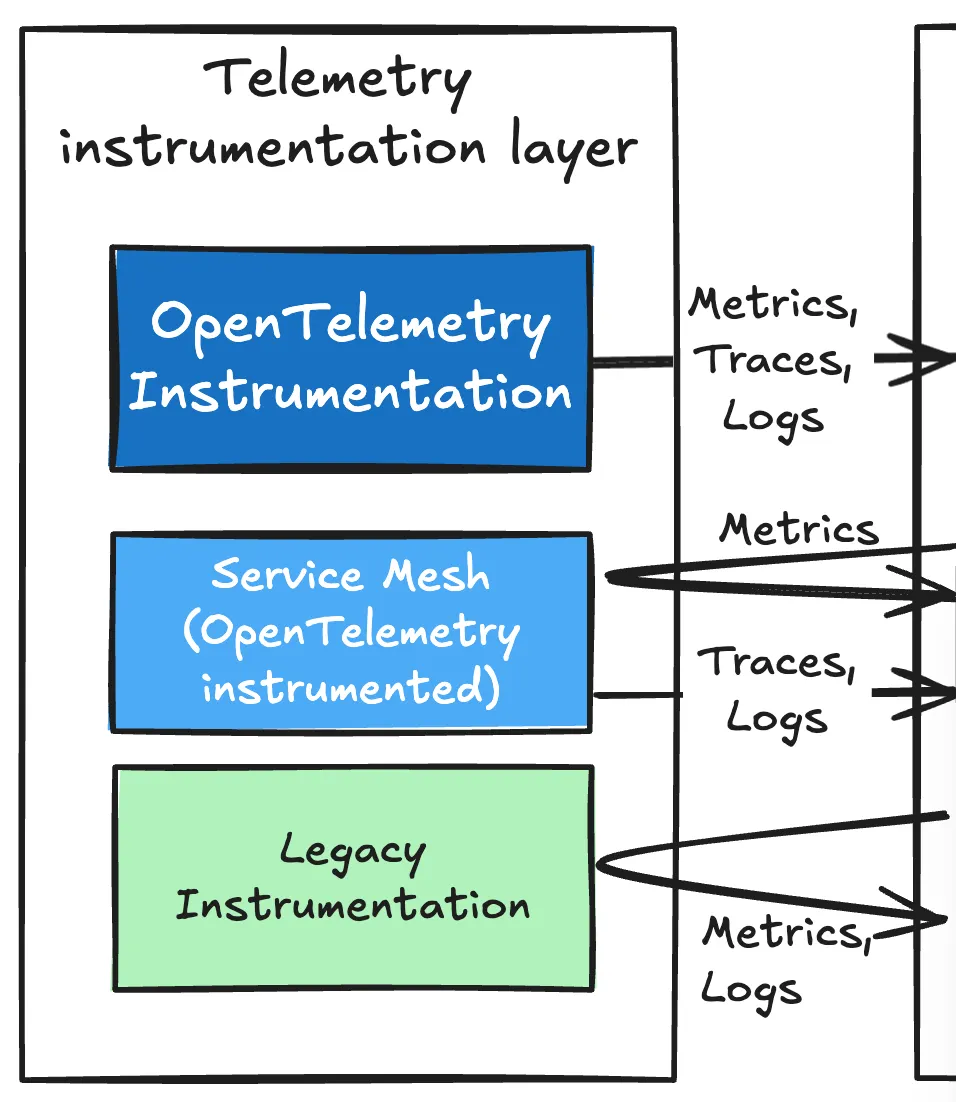
Instrumentation Layer
App에 달라붙어 Telemetry 측정을 이루고 측정된 값을 전송 layer로 전달하는 계층이다.
•
OpenTelemetry Instrumentation: OpenTelemetry는 자체적으로 instrumentation SDK를 제공한다. 코드 내에 직접 적용 가능한 manual instrumetation 뿐 아니라, 소위 ‘Zero-code’를 논하는 자동 instrumentation도 함께 제공한다.
•
Service Mesh: Observability 뿐 아니라 Traffic Management, Security 등의 다른 횡단 관심(Cross Cutting Concerns)까지 고려할 경우 유리하여, 자체적으로 제공하는 값만으로도 OpenTelemetry Instrumentation 없이도 Observability 대부분의 영역을 다룰 수 있다.
참고로 Istio는, log나 trace와는 달리 metric 프로토콜로 Prometheus(OpenMetrics)만을 지원한다. Istio overview: Observability 에서 자세히 다룬다.
Istio overview: Observability 에서 자세히 다룬다.•
Legacy instrumentation: 상기 두 가지에서 측정되지 않는 telemetry는 그대로 두어 OpenTelemetry Collector가 직접 수집하도록 하게 한다. 대표적 예로, 다양한 Prometheus 기반의 exporters와 file system에 위치하는 log가 있다(Trace는 앞선 두 가지 instrumentation 구현체에서 다룬다).
Transportation Layer
Instrumentation 계층에서 받거나 수집한 telemetry를 persistence 계층으로 전달하는 계층이다. 본 과정에서 queueing, retry, 임시 저장 등의 기법 등을 통해 persistence 계층으로 안전하게 telemetry를 전달하는 역할도 함께한다.
전송 layer는 OpenTelemetry Collectors로 일원화 가능하다. 시장에서 사용되는 대부분(?)의 instrumentation 대해 OpenTelemetry가 receiver로 지원하기 때문. Telemetry 별 OpenTelemetry Collector 분류에 대해서는 OpenTelemetry Collector: workload 분류 를 참고한다.
OpenTelemetry Collector: workload 분류 를 참고한다.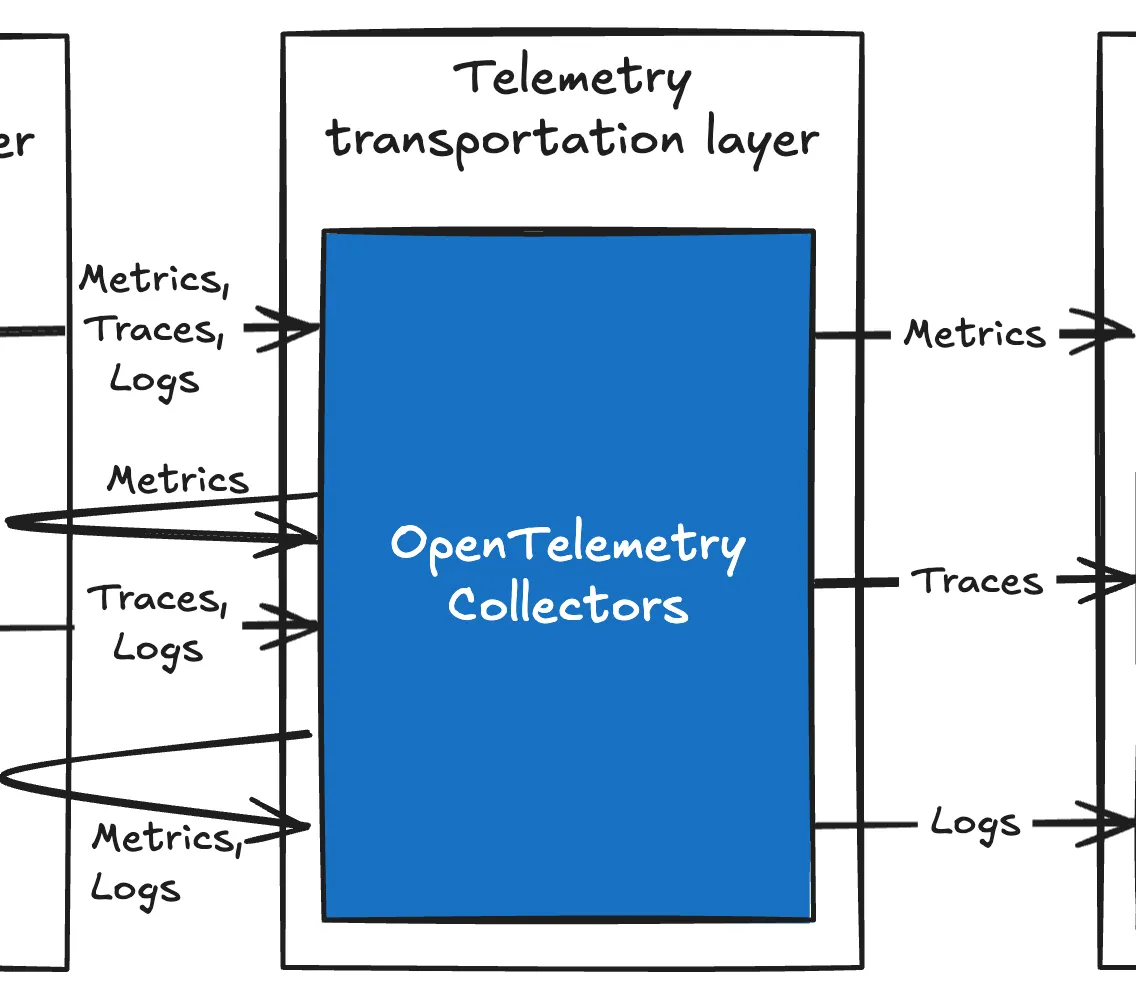
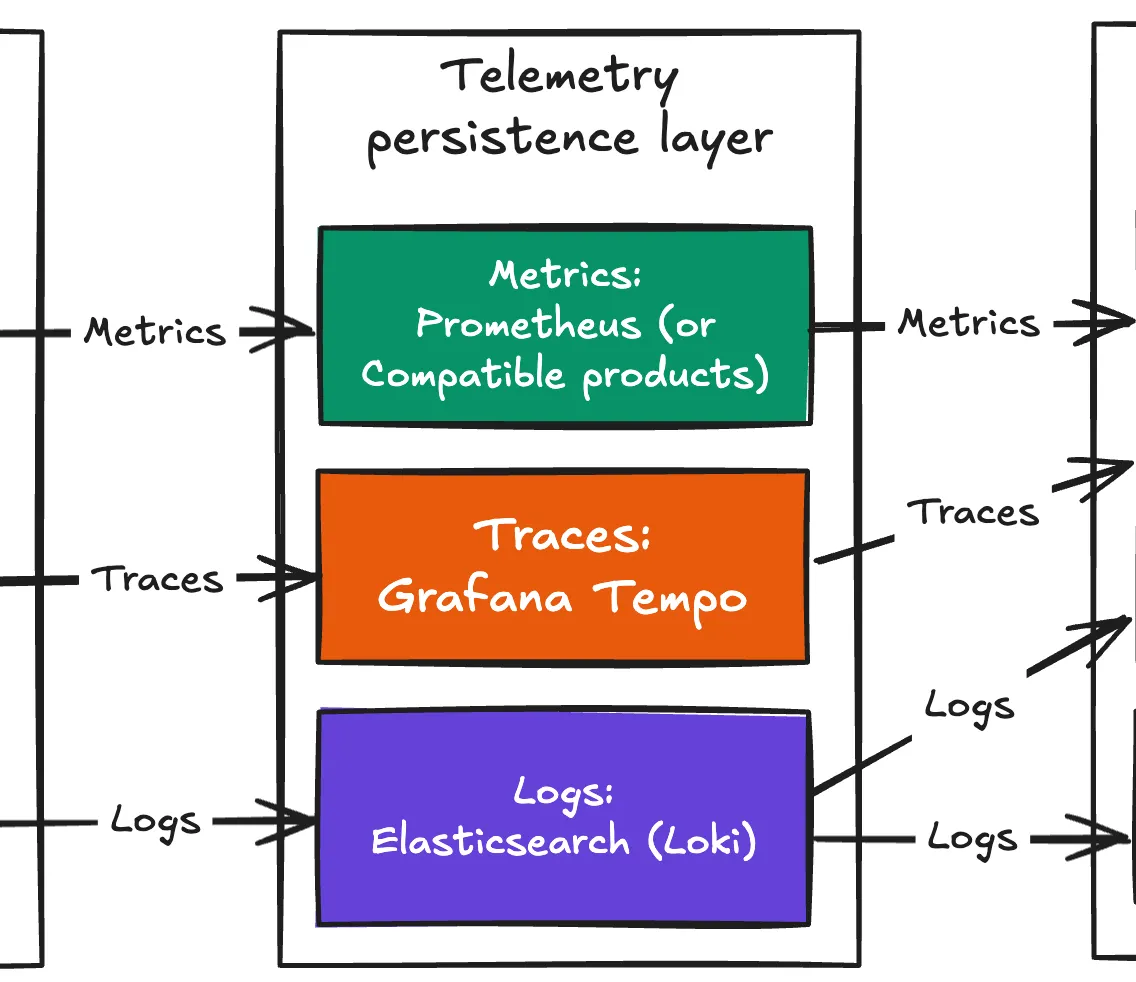
Persistence Layer
Telemetry의 영속적 저장과 함께 Presentation 계층을 위한 telemetry 조회용 engine을 제공하는 계층이다. 본 계층에서 telemetry의 종류(metric, log, trace) 별로 component가 나뉜다. 아래 논한 모든 component는 당연스럽게도 Open Source이자 OpenTelemetry를 지원한다.
•
Prometheus(or Compatible products): Metric 처리용으로, Prometheus 이외에 InfluxDB 등의 타 DB도 고려해볼 수 있으나, OpenTelemetry나 Istio 모두 Prometheus를 default metric DB로 여긴다. 이로 인해, OpenTelemetry는 자체 metric 규격을 가짐에도 별 의미가 없다.
나아가 Prometheus metric 규격은 OpenMetrics란 이름으로 OpenTelemetry와는 별도 표준이 되었다.
Scaling을 고려하여, 실제로는 Prometheus 호환 제품인 Thanos, Cortex, Amazon Managed Prometheus(Cortex 기반)이 주로 사용되는 듯하다.
•
Grafana Tempo: Istio 세계에서 상시 거론되는 trace 제품은 Jaeger이나 persistence는 Elasticsearch 또는 Cassandra에 의존한다. 반면 Grafana Tempo는 persistence를 Amazon S3 등의 object storage를 사용하기에 운영 비용이 대폭 절감되어, 더 많은 sample 운용이 가능하다.
•
Elasticsearch, Loki: Logging solution으로 Elasticsearch가 전통적으로 가장 많이 사용되기에, 특히나 legacy 활용 측면에서 Elasticsearch를 앞세웠다. 근간에는 Grafana Loki가 더 각광을 받는 듯.
Presentation Layer
Telemetry 조회 계층으로 사실 Grafana 하나로 족한데, Persistence Layer에 Elasticsearch를 넣었기에 Kibana는 일종의 꼽사리(?)로 넣었다.
Grafana는 metric, log, trace 모두에 대해 고 품질의 viewer 제공을 가능케 함과 동시에, 무엇보다도 Customizability와 고품질이 특징이기도 하다.
참고로, Grafana는 OpenTelemetry 데이터가 아니더라도 연관 분석을 지원한다. 예컨데 Custom format의 Log더라도, trace ID가 log 내에 위치하면 Trace 화면에서 해당 trace의 Log 화면으로 jump 가능하다.
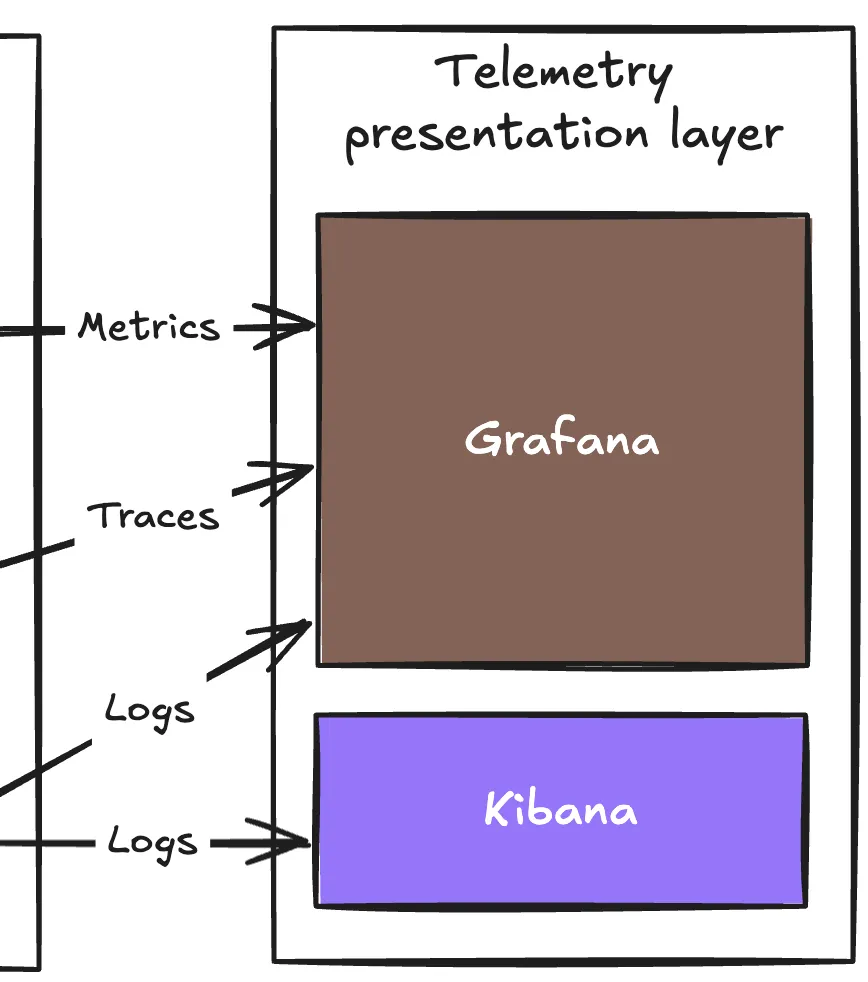
문제는 Istio에서 만들어진 metric과의 연관 분석인데, 해당 metric에 Log, Trace와의 연결 고리에 해당하는 Exemplars를 지원하지 않기에(24.09.12 현재), 이 경우에는 metric 연관 분석은 지원하지 않는다(Metrics 참고)
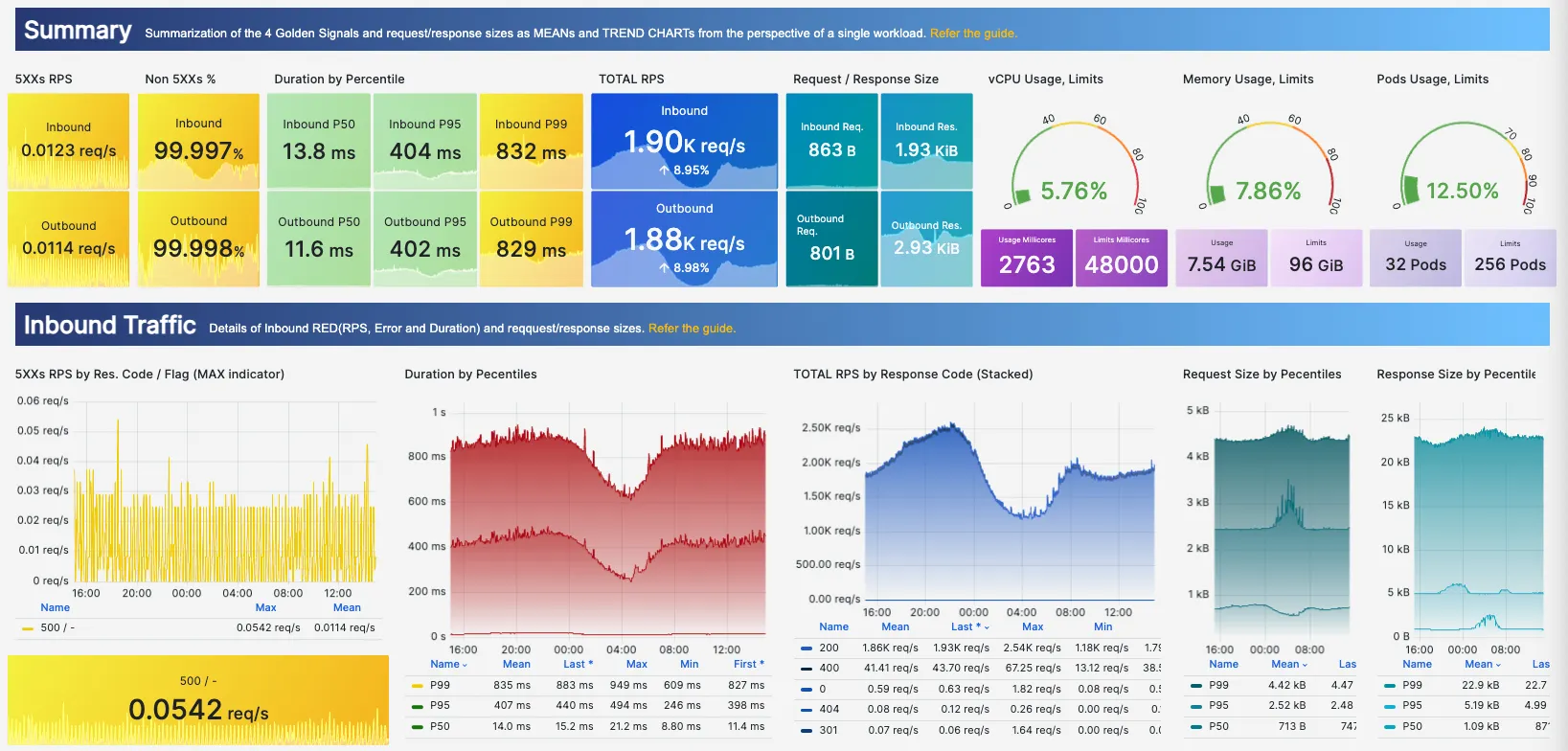
본 아키텍처를 통해 자체 구현된 4 SRE Golden Signals(latency, traffic, errors, saturation)를 나타내는 Grafana Dashboard
References
참조 문서는 대부분 글 내부에 링크로 달았다. 아래는 OpenTelemetry와 Istio 조합 아이디어를 지지하는 글로, 초기 아이디어 검토에 많은 도움을 얻었다(Istio 생성의 주요 멤버가 직원인 solo.io의 글이라 상업적 성격이 포함되었음을 감안해야 한다).

이외에 아래는 Observability 비용 관련한 글과 동영상이다.






