
Who and Why am I here?





My Cluster & its assets
집에서 운영하는 Kubernetes 클러스터 및 여기서 운용되는 서비스로, 아이콘을 클릭하면 각 서비스에 접근 가능합니다. 참고로 개발 서버인 관계로 종종 접근에 실패할 수 있습니다.








최근 글
Search
Introduction
Service Mesh에 대한 overview로, Service Mesh의 대표 제품인 Istio를 통해 Kubernetes를 배경으로 설명한다.
쓰다보니 내용이 길어져 두 편으로 나누어, 본 글 이외의 나머지 편에서는 Features의 Observability, Security, 그리고 Istio 이외의 Service Mesh 제품에 대해 논한다.
Service Mesh란
일단, 정의는 Wikipedia에서 아래와 같이 가져왔다.
프록시를 사용하여 서비스 또는 마이크로서비스 간 서비스 간 통신을 촉진하는 전용 인프라 계층
- Wikipedia, https://en.wikipedia.org/wiki/Service_mesh
Service Mesh는 pod 수준의 L7 traffic 처리를 위한 일종의 overlay network이다. sidecar 등의 기법으로 각 pod에 붙은 proxy가 모든 pod에 대한 in/outbound traffic를 제어함으로, 각종 부가적 features를 추가한다. API Gateway를 cluster 전체에 대한 proxy라 한다면, Service Mesh는 pod에 대한 proxy라 볼 수 있다.
Architecture
아래 그림은 앞선 구조 관점의 Istio의 정의를 나타내는데, Service A와 Service B 사이에서 각 Service에 해당하는 proxy가 traffic을 중계함과 동시에 Control Plane인 istiod는 이들 proxy를 제어하고 있다.

아래 그림에서는 pod 대신 Service라 표현되었다(실제로는 pod에 sidecar가 설치되지만, 개념 및 사용 시에는 Kubernetes Service 단위로 사용된다).
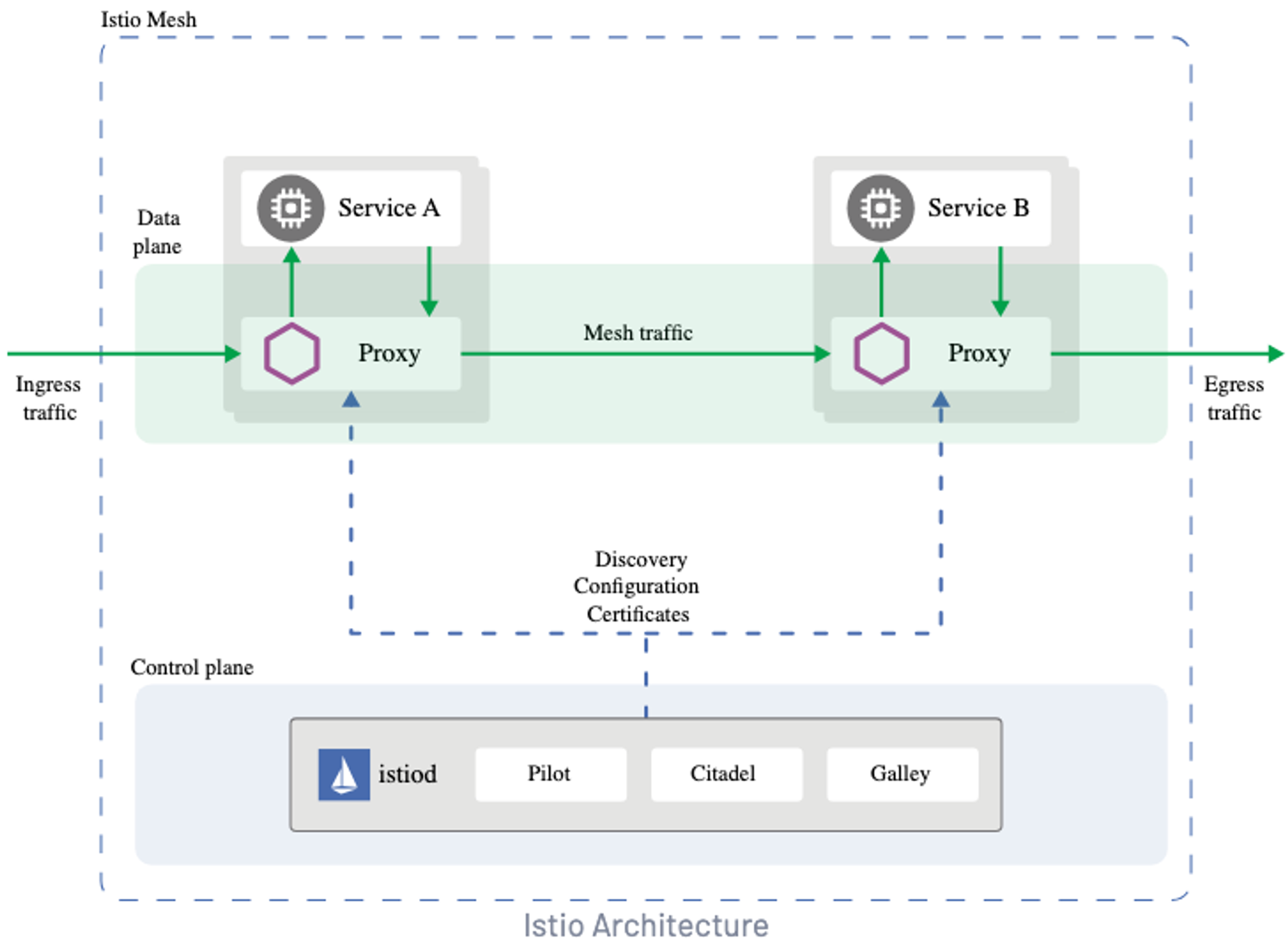
참고: sidecar-less Service Mesh
근래에 sidecar 없는 아키텍처의 Service Mesh가 부각되었는데, Istio는 Ambient Mesh라 하여 Daemon Set(ztunnel)과 Deployment(waypoint)로 envoy proxy의 역할을 나누고, Cilium은 eBPF 기반으로 Daemon Set만을 사용함과 동시에 Control Plane마저 없다. 하지만 sidecar만 없을 뿐 개념적으로는 기존과 동일하다.
타 아키텍처 대비 비교 우위점
Service Mesh overview: Istio 관점으로 1/2
S/W 엔지니어
Envoy
Istio
Service Mesh
Cilium
k8s
Kubernetes
2024/04/27
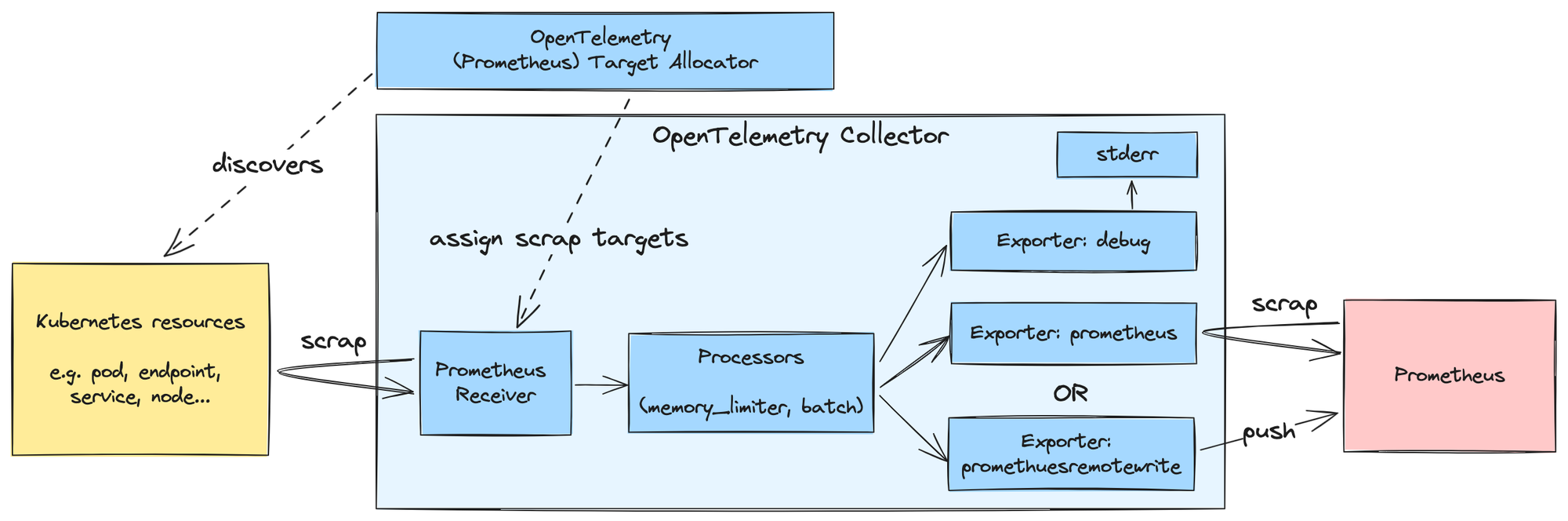
OpenTelemetry Collector 및 Target Allocator의 Kubernetes Metric scrapping 구조
Introduction
OTel(OpenTelemetry) Collector로 Prometheus (scraper - agent mode)를 교체하는 방법에 대한 설명이다. OpenTelemetry의 사용자 관점 Overview 및 OpenTelemetry 설치 준비: OTel k8s Operator 설치 의 연장선 상에 위치한 OpenTelemetry Collector의 상세 검토 중 하나이다.
OpenTelemetry의 사용자 관점 Overview 및 OpenTelemetry 설치 준비: OTel k8s Operator 설치 의 연장선 상에 위치한 OpenTelemetry Collector의 상세 검토 중 하나이다.Summary
•
OTel Collector로 Kubernetes resource metric 스크래핑을 위한 Prometheus를 대체 가능하다.
•
다수의 scraping 대상으로 인한 특정 pod로의 부하 쏠림을 해결하기 위해 Target Allocator가 제공된다.
•
Prometheus로 직접 전달(push)하는 방식과 Prometheus와 동일하게 pull 방식 모두 가능하다.
Architecture
서두에 있는 그림은 OpenTelemetry Collector로 Prometheus (scraper)를 교체했을 때의 아키텍처를 나타낸다.
좌측 노란 박스는 scraping 대상 Kubernetes resources를, 푸른 박스는 OpenTelemetry components로 OpenTelemetry Collector와 Target Allocator를, 붉은 박스는 metric 저장소로서의 Prometheus 및 scraper(오직 OpenTelemetry Collector에서만 scrap)로서의 Prometheus를 나타낸다. 실선은 데이터의 흐름을, 점선은 관계를 나타낸다
각 components에 대한 설명은 아래부터 이어진다.
Components
Architecture 에서 식별된 각 components에 대한 설명이다.
OpenTelemetry Collector로 Prometheus (scraper) 교체하기
S/W 엔지니어
OpenTelemetry
OTel
OpenTelemetry Collector
Prometheus
2024/04/07
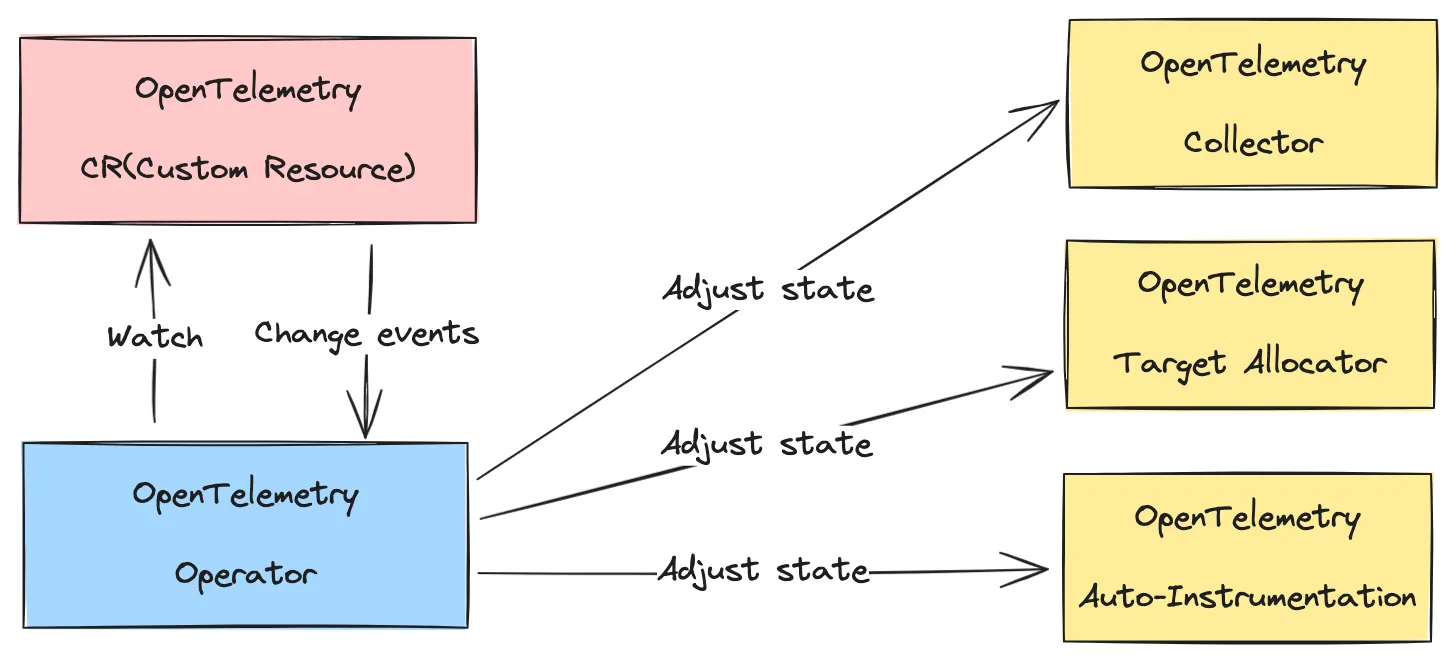
OpenTelemetry Operator를 통한 Collector, Target Allocator, Auto-Instrumentation 설치
Introduction
OpenTelemetry의 사용자 관점 Overview 에서 이어지는 글로, OpenTelemetry 설치를 위한 준비 단계이다.Overview
OTel Collector를 설치 방법은 세 가지로, OTel Collector Kubernetes resource 직접 생성, Helm Chart 이용, 마지막으로 Kubernetes Operator 이용 방법이 있으나, Kubernetes Operator를 이용해야 OTel Collector뿐 아니라 Target Allocator, Auto-Instrumentation도 설치가 가능하다.
앞선 그림은 Otel Kubernetes Operator가 이들 및 OTel CR(Custom Resource)과 어떻게 상호작용하는지를 보여준다(전형적인 Kubernetes CR의 동작 구조 그대를 따른다). 이 Operator 설치 이후의 구체적 Collector, Auto-instrumentation 등의 설치에 대해서는 아래에 이어진다(지속 업데이트 예정).
설치 방법
순서는 다음과 같다.
1.
cert-manager 설치
2.
OTel Kubernetes Operator 설치
cert-manager 설치
설치 방법 출처는 다음과 같다.
OpenTelemetry 설치 준비: OTel k8s Operator 설치
S/W 엔지니어
OpenTelemetry
OTel
Kubernetes Operator
cert-manager
2024/04/06
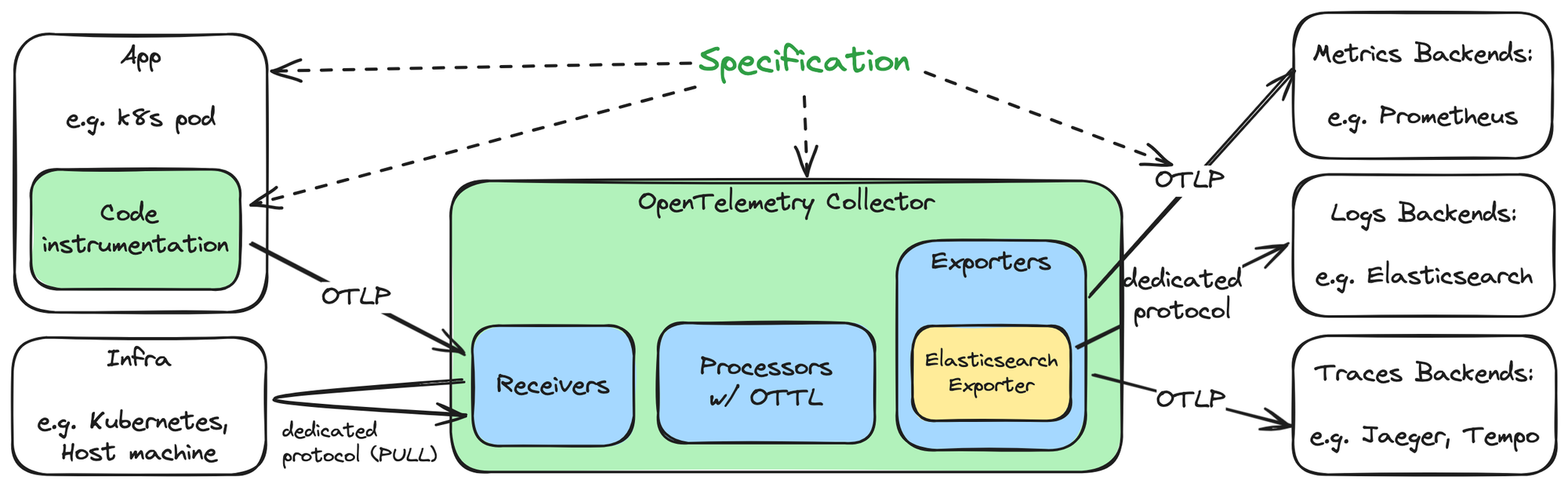
OpenTelemetry의 구조
Introduction
Kubernetes 환경에서의 Observability용 최적 component 조합 검토 중 OpenTelemetry가 수시로 언급됨을 발견. 뿐만 아니라 component 제품마다 이에 대한 지원을 항시 언급. 이즈음 되면 OpenTelemetry는 무시할 수 없는 무엇이 되어버렸다는 뜻.
이 글은 OpenTelemetry에 대한 사용자 관점의 overview이다. 이외에 추후 관련 구현 및 상세 검토를 위해 주요 내용에 대해서는 해당 참조 문서 링크를 달았다.
다음은 OpenTelemetry 공식 홈페이지이자 본문에서 주로 참조한 문서.

Why OpenTelemetry?
1.
MLT 통합 계측: Observability의 핵심인 signal, 즉 MLT(Metrics, Logs, Traces)를 통합 계측, 처리함으로 프로세스 및 아키텍처를 단순화할 뿐 아니라 이들 데이터간 correlation 기반 분석을 촉진한다.
2.
표준화 : MLT 데이터 수집에 대한 표준화된 방법 제공으로 다양한 관찰 도구 및 플랫폼과 더 쉽게 통합 가능하다. 이러한 표준화는 일관성과 호환성을 촉진한다.
3.
최상위권 CNCF 프로젝트 : Open source로서 2024.03.21 현재 CNCF incubating 프로젝트. datadog 등의 특정 업체에게 휘둘릴 일이 없을 뿐 아니라(No Vendor lock-in), 유연성, 상호운용성이 좋다는 뜻. 2023.10 현재 CNCF 프로젝트 중 velocity 2위(1위는 Kubernetes), Linux 재단 프로젝트에서는 3위(1위는 Linux, 2위는 Kubernetes)
4.
주요 Observability 제품 지원: Grafana, Prometheus, Istio 등 Observability (관련) 부문의 주요 Open source 제품 뿐 아니라 Elasticsearch, Datadog, Dynatrace 등 주요 영리 업체도 지원 중이다.
5.
이전 표준 병합: 이전 signal 표준인 OpenTracing과 OpenCensus를 병합. 이들 두 표준의 홈페이지(링크 참조)에 들어가면 모두 OpenTelemetry를 쓰라고 가이드한다.
OpenTelemetry의 사용자 관점 Overview
S/W 엔지니어
OpenTelemetry
Kubernetes
Jaeger
Elasticsearch
Prometheus
Observability
o11y
OTel
OTTL
OTLP
MLT
metric
trace
log
telemetry
2024/03/23

제목: 대칭화, 모듈화, 순서화. ChatGPT 생성 이미지
내 첫 번째 교주님으로 모시는 일론 머스크에 이어 두 번째 교주님이신 박문호 박사가 ‘하사’하신 공부 방법에 대한 썰이다. 참고로 내게 교주님이란 존경하다 못해 돈까지 바치게 만드는 자를 뜻한다. 테슬라 주식 및 ‘박문호 박사의 빅히스토리 공부’ 책은 내가 바친 돈의 예.
일론 머스크야 너무 유명하니 별도로 설명할 필요는 없겠고, 박문호 박사는 ETRI 연구원으로 정년 퇴임하여 현재는 공부 및 이에 대한 전파에 매진하시는 ‘매우 비범한’ 연구자님. 왜 ‘매우 비범한’이란 수식어를 붙였는지는 그의 이력 뿐 아니라 아래 동영상에서 뿜어나오는 지식의 아우라를 직접 느껴보면 안다.


저 유튜브 제목과 부제에서 느껴지는 쌈마이, 사이비스러움이 눈에 거슬리지만, 실상 이 양반이 전하는 무엇은 이들에 정 반대편에 위치한다. 대칭화, 모듈화, 순서화란 이 세 가지가 공부법의 핵심이라고. 맘에 특히나 와닫던 이유 중 하나는 논거가 뇌과학, 즉 인간의 본성에 미치는 데 있다. ‘뇌가 편안해지기 때문에’는 이에 대한 대표적 예.
아래는 이에 대한 요약이라기보다는 나의 이해 및 연상에 더 가깝다.
대칭화
(익힐 여러 대상을) 대칭화하면 기억해야할 정보가 줄어들어 뇌가 편안해지기 때문이고, 나아가 편안해지기에 아름다움까지 지느끼게 된다. - 박문호
대칭이란 어휘는 입자 물리학에서 가져왔다는데 무려 이를 다루는 노이터 정리까지 언급한다(사실 이건 삼천포인데, 난 그 삼천포가 넘 좋았다). 노이터 정리에 대해서는 아래에 따로 적었다.
대칭화란 말이 사실 잘 와닫지 않는데, 대칭화는 사실상 일반화와 동일 의미로 이해된다. 대칭은 불변성을 의미하는데, 일반화란 것이 이 불변성을 각 특수에서 찾는 과정이기 때문.
그가 이렇게 생각한 이유는 어쩌면 당연스러운데, 일반화는 귀납법의 핵심이고 귀납법은 과학에서 진실 획득의 최애 수단이며, 우리는, 특히나 그는 과학의 시대에 살고 있기 때문이다. 해서 귀납법의 선구자들에게 이 공을 돌려야 할지도. 여담으로, 그 선구자는 내 어릴적 맘에 꼳힌 말(진실은 혼돈보다는 과오에서 더 잘 드러난다)을 했던 Francis Bacon으로 보통 일컫는다.
공부법 핵심: 대칭화, 모듈화, 순서화
예술/인문 소감
대칭화
순서화
모듈화
노이터 정리
프란시스 베이컨
뇌과학
박문호
교주님
2024/02/25
근래의 Web 기술 트렌드라는 몇몇 컬럼을 읽다 보니 눈에 걸리는 용어가 보여 간단히 내가 이해한 수준에서 적어 둔다. 몇몇 용어는 새로운 가치를 담았다기에는 무리가 있어 보이기도. 이외 SSG, MDX, ZTA 등 일부는 이미 오랜 용어이지만 이제야 이해했기에 함께 적었다. MDX는 그렇다쳐도 SSG는 나타나 인기를 끈지 10년이 넘은 듯 한데, 뒤쳐진 내가 좀 부끄러워지기도.
아래는 용어 정리를 하게 만든 컬럼 중 일부이다.


PWA(Progressive Web App)
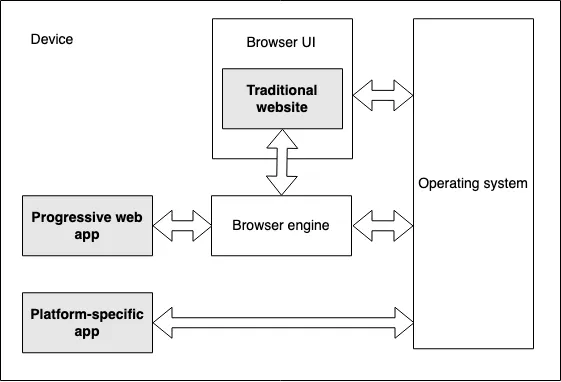
smartphone 초창기부터 계속 이어지던 web으로의 phone app 기술 단일화 - cross platform 개발의 또 다른 시도인 듯. 그나마 기대했고 성과를 내는 듯 했던 Reactive Native, Flutter 조차 어려워 보이던데… PWA는 그래봤자 browser를 그대로 쓰는 web app이라 이질적 UX나 늦은 반응성 문제를 얼마나 해결하는지 의문.
구조적으로 browser가 native 관련 지원을 해야 할 텐데 Android에서는 Google이 PWA tutorial까지 만든 상황이니 그렇다 쳐도, Apple의 경우 이에 대해 공식적인 지원에 대한 언급을 찾기 어려울 뿐 아니라 많은 부분이 지원 안되는 모습을 보이는 도표마저 보이는 중.
•
web 관점: web 기술 기반의 단일 codebase, web에서 직접 접근 가능
•
native 관점: home 화면 icon, app store 기반 설치, background mode / offline 동작, (OS 또는 server) push notification, (browser UI 없는) 전체 화면 동작
References


frontend 관련 트렌드 기술 용어 정리(2024.02)
S/W 엔지니어
SSR
SSG
Headless Architecture
Multi-runtime microservices
ZTA
Zero Trust Architecture
markdown
mdx
2024/02/10



외로움은 내가 어릴 적에 다룰 줄 몰라 한참이나 힘겨워했던 감정이라 나이가 든 지금도 관련 컨텐츠가 보이면 자연스럽게 눈이 간다. 지금은 외로움을 그닥 느끼지 못할 뿐더러 어쩌다 찾아왔다 하더라도 별 어려움 없이 해결하기에, 그 때와는 달리 해결 방법을 찾고자 하는 마음보다는 호기심에 기인한 측면이 크고.
후에야 알게 되었지만 당시의 격한 외로움은 나 뿐이 아니었다. 당시를 회상하며 이야기해보니 지인들 중 많은 사람이 당시 나이에 동일한 감정을 느꼈던 것이다. 우리나라 교육 상황을 보면 놀랍지도 않지만 이는 여전한 할 뿐 아니라 더할지도 모른다는 생각이 스친다. 당시보다 불평등과 경쟁은 심화되었으니. 실제 외로움의 주된 원인인 ‘능력주의’를 나의 세대와 현 20대가 공유한다고.
아래는 ‘외로움의 습격’이란 책의 작가가 본인의 책 내용을 다루는 영상으로, 이어지는 글은 덧붙임이 가미된 영상의 요약이다. 약 3/5 지점까지를 다루는데 그 이후는 그다지 새롭지 않아 생략했다(외로움의 또 다른 원인인 불평등을 논의). 덧붙임은 말머리에 으로 표시했다.
으로 표시했다.

외로움으로 고통 받는 한국, 특히 20대
•
외로움은 쓸모없는 존재, 주변의 도움을 받지 못하는 존재라고 느끼는 상태. 외로움은 행복의 주요 척도 중 하나. 그런 면에서 한국은 OECD 중 최악.
•
20대가 특히 외로운 상태. 미국(밀레니얼 세대), 유럽(Y 세대), 한국(MZ 세대) 등 전 세계적으로 그러함. 특히 한국은 약 40%가 외로움을 느끼며, 현재 60만명이 6개월 이상 타인을 만나길 꺼려함.
외로움(loneliness)의 어원
•
lonely란 형용사가 처음 만들어진 셰익스피어 시절에 처음 만들어진 단어. 유사 의미의 alone은 중세에 신을 마주하는 뜻으로 오히려 긍정적 의미의 고독(solitude)과 유사.
•
외로움에 빠지면 위험한 생각을. 이 내용으로 셰익스피어의 코리올레이너스란 작품에 lonely dragon이란 표현이 등장.
외로움(loneliness)와 고독(solitude)의 차이
‘외로움’의 원인, 능력주의
自省(Introspect) / 세상살이
외로움
고독
능력주의
한나 아렌트
김만권
외로움의 습격
전체주의의 기원
2024/02/03

Motivation
storage에 저장된 데이터는 app 또는 cluster의 lifecycle과는 별개로 다룰 필요는 항시 발생하기 마련이다. 예컨데 Docker Registry app에서 많은 container image를 저장했을 때, (memory 부족 등 어떤 이유에서건) Docker Registry app 또는 cluster 자체를 재기동해야 하는 경우가 있다. 이를 해결하기 위한 구체적 요구사항은 다음이 될 것이다.
1.
app이 삭제되더라도 데이터는 삭제되지 않도록
2.
기존 데이터를 신규 app과 cluster에서 사용 가능하도록
kind가 사용하는 기본 Storage class (standard)인 local-path-provisioner는 hostPath로의 dynamic provisioning을 위함인데, 이 특성 상 사전에 PVC (Persistent Volume Claim)를 지정하지 않으면 새로운 PV (Persistent Volume)를 생성하기에 2번 요구사항과 상충한다. 또한 이 storage class의 default reclaim policy는 PVC가 삭제될 경우 해당 PV도 함께 삭제하는 Delete이므로, 1번 요구사항과도 충돌한다.
Summary
기존 storage와 PV 간 binding, PV와 PVC 간 binding, 그리고 pod가 binding을 마친 PVC를 사용하도록 설정함으로 기존 storage 재사용이 가능하다.
설명
Summary에서 논한 두 가지 binding과 이를 통해 만들어진 PVC 사용 설정에 관한 상세 내용이다.
기존 storage와 PV 간 binding
기존 storage 재사용 in kind (w/ 데이터 유지)
S/W 엔지니어
kind
k8s
MyCluster
PV
재사용
PVC
Kubernetes
2024/01/04

아래는 My Cluster란 프로젝트로서, Kubernetes 자체를 포함한 여러 app을 스터디, 개발, 테스트하기 위해 사용하고, 사용 중인 프로젝트이다.

가장 중점을 둔 부분은 Kubernetes 자체를 포함하여 app을 빠르게 생성/제거 가능한 점이다. 무언가 제대로 파악하기 위해서는 쉽게 물고 뜯고 복구할 수 있어야 하는데, 생성/제거는 가장 큰 장벽이 되곤 하기 때문이다.
참고로, 이 블로그 대문의 My Cluster & its assets에 링크된 여러 app은 이를 기반으로 운용되며, 그냥 집에 있는 오래된 notebook(Macbook pro 2011년 산)에서 동작한다. 리소스 별루 안 잡아먹는다는 뜻.
작년 초에 처음 만들었지만 범용화에는 이래저래 걸리는 게 많아 공개가 늦어졌다. DRAFT 딱지를 붙였는데, 떼려면 좀 더 있어야 할 듯. 각 app 별 생성/삭제 뿐 아니라, 특히 Home server/cluster로 운용하기 위한 설명이 부족하다. 업데이트 하는대로 이 글도 함께 업데이트 예정.
아래는 이 프로젝트의 README.md이다.
My Cluster (DRAFT)
단일 host에서 Kubernetes와 여기서 운용할 여러 app을 ‘빠르게’ 설치/삭제하기 위한 프로젝트로서, 이들에 대한 사용법 확보 및 테스트가 주된 목적이다.
My Cluster - Home k8s cluster
S/W 엔지니어
Kubernetes
MyCluster
kind
k8s
Home Server
2024/01/01
Load more
카테고리 별 글
Search
음악인
13
Load more
S/W 엔지니어
108
Load more
예술/인문 소감
70
Load more
自省(Introspect) / 세상살이
69
Load more
프로젝트s
92
Load more
방명록 백업